|
|
|
|
INTRODUCERE - CRESTEREA PERFORMANTEI CALCULUI IN VIRGULA MOBILA
Lucrarea prezenta trateaza optimizarea aplicatiilor in virgula mobila continand instructiuni SIMD (single-instruction, multiple-data) in virgula mobila si cuprinde reguli generale de optimizare a codificarii in virgula mobila si exemple ce ilustreaza tehnicile de realizare a optimizarii.
Principalele reguli si sugestii referitoare la acest lucru includ urmatoarele:
Intelegerea modului in care compilatorul manevreaza codul in virgula mobila, determinarea cauzei pentru care acesta nu creeaza cel mai rapid cod.
Identificarea dependentelor ce pot fi rezolvate: operatii aritmetice in virgula mobila cu latenta mare, localizare cache slaba, solicitari mari de memorie.
Utilizarea unei precizii mari trebuie facuta doar atunci cand este necesara. Precizia simpla (32 biti) este mai rapida in anumite operatii si consuma doar jumatate din spatiul de memorie utilizat de precizia dubla (64 biti) sau precizia extinsa (80 biti).
Utilizarea unor rutine rapide float-to-int apeland la instructiunea FISTTP daca se foloseste setul de instructiuni SSE3 sau la instructiunile cvttss2si si cvttsd2si pentru Streaming SIMD Extensions 2. Multe biblioteci realizeaza mai multa munca decat este necesar. Instructiunea FISTTP in SSE3 poate realiza conversia valorilor in virgula mobila la valori intregi pe 16-biti, 32-biti sau 64-biti folosind trunchierea fara a accesa cuvantul de control virgula mobila (floating-point control word - FCW). Instructiunile cvttss2si / cvttsd2si scutesc de multe bucle si uneori reduc diferenta dintre intarzierile cauzate de accesul la memorie prin copierea si stocarea instructiunilor si datelor curente. Acest lucru evita schimbarea regulii de rotunjire.
Asigurarea nedepasirii domeniului de valori al aplicatiei. Numerele ce nu sunt reprezentabile in domeniul de valori definit determina supraincarcari foarte mari.
Inlaturarea dependentelor in lant acolo unde este posibil. Acest lucru va permite masinii sa extraga cat mai mult ILP din cod. La adunarea elementelor unui vector se vor folosi sume partiale in locul unui singur acumulator. Spre exemplu, pentru a calcula z = a + b + c + d, in loc de a scrie:
x = a + b;
y = x + c;
z = y + d;
se va folosi:
x = a + b;
y = c + d;
z = x + y;
Programarea codului in limbaj de asamblare utilizand instructiunea FXCH. Utilizarea tehnicii de unroll pentru bucle si a celei de prelucrare in conducta a instructiunilor (pipeline).
Realizarea unor diverse transformari pentru imbunatatirea accesarii memoriei. Utilizarea fuziunii de bucle sau a compresiei acestora pentru a mentine procesarea cat mai mult la nivelul memoriei cache.
Mascarea intreruperilor pentru obtinerea unei performante mai bune. Atunci cand intreruperile sunt nemascate, performanta softului este scazuta.
Utilizarea instructiunilor si registrilor tehnologiei MMX pentru copierea datelor ce nu sunt utilizate mai tarziu in codificarea in virgula mobila SIMD.
Utilizarea instructiunilor reciproce urmate de iteratii pentru o acuratete crescenta. Aceste instructiuni produc o acuratete scazuta dar se executa mult mai rapid. A se lua in considerare urmatoarele:
- daca o acuratete redusa este acceptabila, este indicata folosirea acestor intructiuni fara iteratie;
- daca o acuratete aproximativ totala este necesara, atunci se va utiliza o iteratie Newton-Raphson;
daca o acuratete totala este necesara, atunci este indicata utilizarea tehnicii "divide and square root" ce furnizeaza o acuratete mai mare dar incetineste performanta.
Reorganizarea programelor (scheduling) reprezinta procesul de aranjare a instructiunilor din cadrul unui program obiect astfel incat acesta sa se execute pe arhitectura hardware intr-un mod cvasioptimal din punct de vedere al timpului de procesare. Procesul de reorganizare a instructiunilor determina cresterea probabilitatii ca procesorul sa aduca simultan din cache-ul de instructiuni mai multe instructiuni independente. De asemenea asigura procesarea eficienta a operatiilor critice din punct de vedere temporal in sensul reducerii prin mascare a latentelor specifice acestor operatii. Este rezolvata demult problema optimizarii 'basic block'-urilor, adica a acelor unitati secventiale de program care nu contin ramificatii si nu sunt destinatia unor instructiuni de ramificatie. Cel mai utilizat algoritm euristic in acest sens este cunoscut sub numele de "List Scheduling". Acesta parcurge graful dependentelor asociat unitatii secventiale de program de jos in sus. In fiecare pas se incearca lansarea in executie a instructiunilor disponibile. Dupa ce aceste instructiuni au fost puse in executie, instructiunile precedente devin disponibile spre a fi lansate in pasul urmator. Fiecarei instructiuni i se ataseaza un grad de prioritate egal cu latenta caii instructiunii. Algoritmul da rezultate cvasioptimale si are avantajul parcurgerii grafului dependentelor de date asociat "basic-block"-ului intr-o singura trecere.
O alta tehnica de scheduling esentiala tine de optimizarea buclelor de program. Aceasta optimizare este foarte importanta pentru ca in buclele de program se pierde cea mai mare parte a timpului de executie aferent respectivului program, dupa regula binecunoscuta care afirma ca '90% din timp executa cca. 10% din program'. Aici, 2 tehnici sunt mai uzitate: tehnica "Loop Unrolling" respectiv tehnica "Software Pipelining".
Tehnica "Loop Unrolling" se bazeaza pe desfasurarea buclelor de program si apoi, reorganizarea acestora ca basic - block - uri prin algoritmi de tip "List Scheduling". Prin aceasta desfasurare a buclei de un numar de ori se reduce si din efectul defavorabil al instructiunilor de ramificatie.
Tehnica "software pipelining" este utilizata in reorganizarea buclelor de program astfel incat fiecare iteratie a buclei de program reorganizata sa contina instructiuni apartinand unor iteratii diferite din bucla originala. Aceasta reorganizare are drept scop scaderea timpului de executie al buclei prin eliminarea hazardurilor intrinseci, eliminand astfel stagnarile inutile pe timpul procesarii instructiunilor.
Tratarea instructiunilor cu latente mari. Instructiunile a caror executie necesita mai mult de un ciclu se numesc instructiuni "cu latente mari". Astfel de instructiuni sunt cele de inmultire, impartire, flotante si cele cu referire la memorie. Numarul de cicli in care se executa o instructiune load depinde de numarul de cicli necesari accesarii datei din cache-ul de date sau din memoria interna. Cand o astfel de instructiune se infiltreaza intr-un nou grup de instructiuni, acest grup trebuie sa nu contina instructiuni care folosesc ca sursa registrul destinatie al instructiunii load. In timpul rularii procesul va stagna pana cand executia instructiunii load se va fi incheiat, scheduler-ul nefiind unul optim.
Optimizarea paralelismului
Procesoarele Pentium dispun de o unitate pentru procesarea pipeline in virgula mobila Notiunea de pipeline (in traducere - conducta) reprezinta suma unor etape pe care instructiunile trebuie sa le parcurga pana la obtinerea rezultatului final. Pipeline-ul este impartit in stagii, fiecare avand o sarcina bine definita. Iata un exemplu de pipeline simplu, fiecare stagiu ocupand exact timpul unui ciclu de tact.
Stagiul 1: fetcher - pregateste urmatoarea instructiune
Stagiul 2: decoder - decodifica urmatoarea instructiune
Stagiul 3: ALU - executa instructiunea
Stagiul 4: retire unit - aduce rezultatul inapoi in memorie
Desigur, toate aceste operatii puteau fi executate neorganizat, insa pentru un pipeline cu patru stagii avem patru operatii care sunt realizate simultan in locul uneia singure. Pipeline-ul a fost gandit tocmai pentru a oferi posibilitatea executiei simultane a mai multor instructiuni si, in cazul ideal, performanta este multiplicata de un numar de ori dat de lungimea pipeline-ului. Astfel, daca procesorul are de executat 100 de operatii, fiecare necesitand cate patru stagii, vor fi necesare doar 100 de cicluri de tact in locul a 400, pe fiecare ciclu fiind executate cate patru operatii. Din pacate, situatia ideala nu este intalnita niciodata pentru ca instructiunile depind unele de altele mai mult decat pare la prima vedere. Astfel daca o instructiune nu poate fi executata decat dupa ce primeste de la alta un rezultat, ea va ramane blocata in pipeline pana cand primeste unda verde sau va fi eliminata din pipeline, executia ei fiind amanata si lasand loc altor instructiuni care pot fi executate la acel moment. Este evident ca sansele ca acest eveniment sa aiba loc cresc odata cu cresterea numarului de stagii, tot mai multe instructiuni fiind "blocate in trafic". Situatia descrisa duce la aparitia timpilor morti, in care procesorul nu se incalzeste si de care se poate profita, crescandu-i-se frecventa.
Prin reorganizarea (rearanjarea) instructiunilor in virgula mobila se pot optine rezultate maxime ale unei unitati de calculul in virgula mobila a unui processor Pentium. Aditional, aceste optimizari pot duce la o imbunatatire a procesarii pipeline in virgula mobila. Se va considera exemplul din imagine:
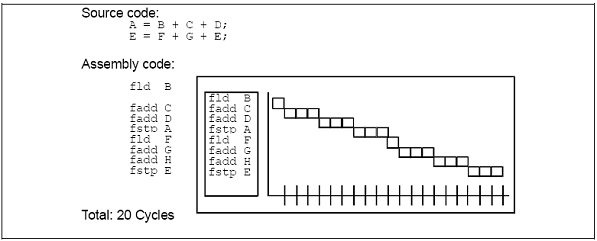
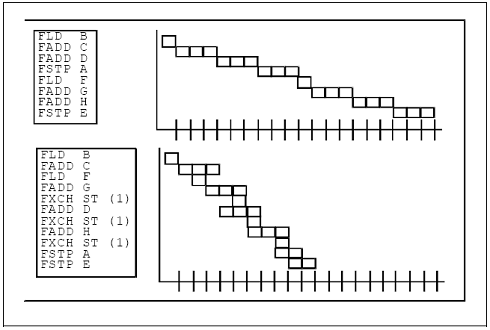
Pentru a exploata capacitatea procesarii paralele a procesoarelor Pentium, trebuiesc determinate instructiunile ce pot fi executate in paralel. Cele doua operatii in limbaj de programare la nivel inalt din exemplul de mai jos sunt independente, astfel instructiunile corespunzatoare in limbajul de asamblare vor putea fi planificate pentru a fi executate in parallel, obtinandu-se astfel o imbunatatire la nivelul vitezei de executie a codului.
Codul sursa:
A = B + C + D;
E = F + G + E;
fld B fld F
fadd C fadd G
fadd D fadd H
fstp A fstp E
Majoritatea operatiilor in virgula mobila necesita ca un operand si rezultatul lor sa utilizeze varful stivei. Acest fapt determina dependenta fiecarei instructiuni de cea care ii precede si inhiba intersectarea instructiunilor. O modalitate evidenta de a preintampina acest neajuns este aceea de a ne imagina existenta unui refistru in virgule mobile liber, in locul stivei. Codul ar arata astfel:
fld B TF1
fadd F1, C TF1
fld F TF2
fadd F2,G TF2
fadd F1,D TF1
fadd F2,H TF2
fstp F1 TA
fstp F2 TE
Cu scopul de a implementa acesti registrii imaginary va fi necesara utiliyarea instructiunii fxch pentru modificarea valorii in varful stivei. Este un mod de evitare a dependentei fata de varful stivei. Instructiunile fxch pot fi associate cu operatiile obisnuite in virgula mobila, astfel incat nu exista nici un cost la procesoarele Pentium. In mod additional, fxch nu utilizaeza cicluri suplimentare in cazul procesoarelor Pentium.
STO ST1
fld B TF1 fld B B
fadd F1, C TF1 fadd C B+C
fld F TF2 fld F F B+C
fadd F2,G TF2 fadd G F+G B+C
fxch ST(1) B+C F+G
fadd F1,D TF1 fadd D B+C+D F+G
fxch ST(1) F+G B+C+D
fadd F2,H TF2 fadd H F+G+H B+C+D
fxch ST(1) B+C+D F+G+H
fstp F1 TA fstp A F+G+H
fstp F2 TE fstp E
La procesoarele Pentium, instructiunile fxch sunt associate instructiunilor precedente fadd, executandu-se in parallel cu acestea. Instructiunile fxch muta un operand pentru urmatoarea instructiune in virgula mobila, aceasta rezultand intr-o imbunatatire la nivelul vitezei de executie a procesoarelor Pentium, dupa cum se vede in figura de mai jos.