|
|
|
|
Acest document reprezinta materialul/suportul scris pentru cursul de instruire 02624 - Baze de Date: Sisteme si Concepte Relationale.
Invatarea conceptelor si a terminologiei de baza a bazelor de date relationale pentru comunicarea in mediul informational sau ca un prim pas al instruirii in domeniul aplicatiilor unui sistem de baze de date relational.
ATRIBUT :
- informatie referitoare la o entitate care serveste la identificare, descriere, clasificare, calificare, cuantificare sau care exprima starea acelei entitati.
FUNCTIA:
- o activitate care trebuie sustinuta de catre organizatie, fie acum, fie in viitor, cu scopul ca organizatia sa poata sa-si atinga obiectivele definite.
FUNCTIA ACTIVITATE ELEMENTARA :
- o functie care preia activitatea dintr-o anumita stare de consistenta intr-o alta sau care nu modifica deloc starea activitatii.
ENTITATE :
- ceva semnificativ pentru care trebuie cunoscute sau pastrate informatii.
INTEGRITATEA ENTITATII :
- reguli care asigura consistenta continutului bazei de date.
DECOMPOZITIE FUNCTIE :
- un proces iterativ prin care functia de nivel inalt este descompusa intr-un set de functii de 'nivel urmator', fiecare dintre ele fiind descompuse in acelasi mod.
MODEL :
- reprezentare simplificata sau descriere a unui sistem sau entitati complexe.
INTEGRITATE REFERENTIALA :
- reguli definite pentru un set de coloane care permit inserarea sau actualizarea numai a valorilor care exista in alt tabel.
RELATIE :
- ce influenta are un anumit tip de entitate asupra celeilalte.
SUB-TIP :
- un set discret de caracteristici ale unei entitati.
SUPER-TIP :
- o entitate care a fost sub-impartita intr-un numar de entitati similare denumite sub-tipuri.
Abrevieri
EBF - Functie Elementara
ERD - Diagrama Entitate-Relatie
ERM - Model Entitate-Relatie
FHD - Diagrama Ierarhica de Functii
FM - Model Functie
MM - Model Matrice
OM - Model Obiect
UID - Identificator Unic
Note de curs: Programare non-procedurala cu SQL si SQL*Plus - Oracle Corporation
Conceptele Oracle 8 Server - Oracle Corporation
Modelarea si Proiectarea Bazelor de Date - Principii Fundamentale - Seria Morgan Kaufmann in Sisteme de Management al Datelor, Toby J. Teorey
Business Modeling Techniques - Course Notes Edition 1.1
Model Business Systems with Designer/2000 - Course Notes Edition 1.2
Nu.
Tehnologia bazelor de date a inlocuit sistemele de fisiere. Componenta de baza a unui fisier intr-un sistem de fisiere este articolul, care reprezinta cea mai mica unitate de date (nume, cantitate etc.). Un grup de articole de date inrudite reprezinta o inregistrare (comanda, persoana de vanzari, beneficiar etc.). Un fisier este o colectie de inregistrari de un singur tip. Sistemele de baze de date au construit si au extins definitiile: intr-o baza de date relationala un articol este numit atribut, o inregistrare este numita rand sau n-tuple si un fisier este numit tabela.
Scopul general al bazei de date este a a pastra si regasi informatiile. Baza de date are o structura logica si structuri fizice. Motivatia utilizarii mai degraba a bazelor de date decat a fisierelor a fost disponibilitatea mai mare de a permite diverse seturi de utilizatori, integrarea datelor pentru un acces mai usor si actualizarea tranzactiilor complexe si o redundanta mai redusa a datelor.
Un sistem de gestionare abazelor de date (SGBD sau DBMS) este un sistem software generalizat pentru manipularea bazelor de date. Un DBMS permite:
1. Vizualizare logica (schema, sub-schema)
2. Vizualizare fizica (metode de acces, clustering)
3. Limbaj de definire a datelor (DDL)
4. Limbaj de manipulare a datelor (DML)
5. Utilitare cum ar fi gestionarea tranzactiilor si controlul concurentei, integritatea datelor, salvare in caz de avarie si securitate
Sistemele de gestionare a bazelor de date s-au dezvoltat de la:
- sisteme ierarhice
- retea
conexiuni exprimate prin pointeri
ambele modele precedente necesita cunostinte despre caracteristicile logice si fizice ale modelului de date.
pana la
- modele relationale
conexiuni exprimate numai prin date
proiectantul bazei de date se focalizeaza pe caracteristicile logice si fizice
separat
la
- modele orientate-obiect
urmatoarea generatie este bazata de asemenea pe separarea aspectelor logice si fizice, dar merge mai departe prin integrarea mecanismelor de manipulare a datelor si de definire a datelor.
Astazi, modelul de baza de date acceptat pe scara larga este modelul relational. In 1970 E.F.Codd a publicat 'Un model relational de date pentru banci mari de date comune'. El a propus un model relational care imita procesele de algebra relationala care implica:
- o colectie de obiecte cunoscute ca relatii
- un set de operatii care actioneaza asupra relatiilor pentru a produce noi relatii.
O relatie poate fi gandita sub forma unei tabele. Regasirea datelor este realizata prin intermediul operatiilor relationale pe aceste tabele.
Referitor la tabele ideile ce trebuie avute in vedere sunt urmatoarele:
COLOANE
O tabela este alcatuita din coloane verticale de date, pana la 256. Fiecare coloana e referita printr-un nume si pastreaza date de tip si dimensiune specifice si contine o infomatie importanta (de exemplu, numai functia salariatilor pentru toti salariatii).
CHEI PRIMARE
O colana care defineste unicitatea unui rand (de exemplu, numar salariat). Poate fi definita o singura cheie primara pe tabela.
CHEI STRAINE
O coloana care defineste modul in care tabelele se relationeaza intre ele (de exemplu, numarul departamentului din tabela salariati trebuie sa adreseze numarul din tabela departamente).
CAMP
La intersectia unui rand cu o coloana se afla un camp. Campul poate contine sau nu date.
Operatorii relationali sunt utilizati pentru a extrage datele si a combina datele pentru a fi extrase. Acestia sunt urmatorii:
RESTRICTION
afiseaza anumite randuri dintr-o relatie (subset orizontal)
PROJECTION
afiseaza anumite coloane dintr-o relatie (subset vertical)
PRODUCT
rezultatul concatenarii randurilor a doua seturi de date. Toate randurile din primul set sunt concatenate cu randurile din al doilea set. De multe ori se va produce un nou set foarte mare.
JOIN
rezultatul concatenarii dupa conditii specifice a randurilor din doua seturi de date.
UNION
afiseaza randurile unice care apar intr-una sau in ambele relatii. UNION ALL poate fi utilizat pentru a afisa toate randurile care apar intr-una sau in ambele relatii.
INTERSECTION
afiseaza toate randurile care apar in ambele din cele doua relatii.
DIFFERENCE
afiseaza randurile care apar numai intr-una dintre relatii.
Ciclul de viata al bazei de date incorporeaza pasii necesari pentru proiectarea unei scheme logice globale a bazei de date. Odata ce proiectarea este terminata, ciclul de viata continua cu implementarea si intretinerea bazei de date.
Cerintele bazei de date sunt determinate prin intervievarea atat a producatorilor cat si a utilizatorilor de date. In urma acestora se realizeaza specificatii formale. Specificatiile includ datele necesare si relationarea lor.
Schema globala care prezinta toate datele si relatiile dintre ele este dezvoltata utilizand tehnicile de modelare conceptuala a datelor cum ar fi modelul entitate-relatie (ERM), modelul obiect (OM). Modelul de date trebuie transformat in cele din urma in relatii normalizate (globale) sau tabele.
In prezentul curs, accentul va fi pus pe ERM versus alte tehnici de modelare.
Specificatiile de date sunt analizate si modelate prin utilizarea unei diagrame relatie-entitate (ERD). A se vedea sectiunea "Modelul de Date".
De obicei proiectul este de dimensiuni mari, asa incat vor rezulta vederi si relatii multiple. Pentru a elimina redundanta si inconsistenta, vederile trebuie consolidate intr-o singura vedere globala.
Pasii de baza:
1. Analiza anterioara integrarii: abordari binare sau n-are ale integrarii schemelor
2. Compararea schemelor: detectarea conflictelor de denumire (sinonime, omonime), structura, dependenta, cheia, conflictelor de comportare
3. Conformitatea schemelor: rezolutia conflictelor, conversia la un tip de model de date primitiv, generalizarea, adaugarea de noi relatii
4. Restructurarea schemelor: tinand cont de urmatoarele
totalitate (sa apara toate componentele),
minimizare (indepartarea redundantei) si
comprehensibilitate (sa aibe un sens pentru utilizator).
Pe baza caracterizarii conceptelor ERM si a unui set de reguli de mapare, fiecare relatie si entitatile asociate acesteia sunt transformate intr-un set de tabele relationale candidate.
1. Reguli de transformare
Transformarile de baza pot fi descrise in termenii a trei tipuri de tabele care produc:
O tabela entitate cu acelasi continut de informatii ca si entitatea originala
O tabela cu cheie straina a tabelei parinte
O tabela relationala cu cheie straina pentru toate entitatile din relatie
2. Pasii de transformare
Transforma fiecare entitate intr-o tabela continand atributele cheie si non-cheie ale entitatii
Transforma fiecare relatie M-M intr-o tabela relationala cu cheie a entitatilor si atributelor relatiei
Dependentele functionale (FD) sunt derivate din ERD. Ele reprezinta dependentele dintre elementele de date care sunt cheie de entitati. Dependentele aditionale pot deriva din specificatii printre atribute cheie si non-cheie in cadrul entitatilor. Tabelele relationale asociate candidate impreuna cu toate dependentele derivate sunt normalizate in cel mai inalt grad utilizand tehnicile de normalizare standard. In cele de urma, redundantele care apar in tabelele normalizate candidate sunt analizate in continuare pentru posibile eliminari, cu constrangerea ca integritatea datelor sa fie pastrata. A se vedea sectiunea "Normalizare".
Consta in selectarea proceselor dominante pe baza celei mai mari frecvente, volum sau prioritate explicita. Definirea extensiilor simple ale tabelelor va imbunatati performantele de cautare, actualizare si pastrare, tinand cont de posibilele efecte ale denormalizarii.
Fragmentarea datelor si alocarea sunt de asemenea forme de proiectare fizica deoarece ele trebuie sa ia in considerare mediul fizic adica configurarea retelei. Acest pas este separat de schema locala si de proiectarea fizica deoarece deciziile de proiectare pentru distributia datelor sunt facute inca independent de DBMS locala.
O schema de fragmentare descrie maparea 1-M utilizata penru a partitiona fiecare tabela globala in fragmente. Fragmentele sunt portiuni logice ale tabelelor globale ce sunt localizate fizic pe unul sau mai multe site-uri ale retelei (logic).
O schema de alocare a datelor desemneaza unde va fi pastrata fiecare copie a fiecarui fragment. O mapare 1-1 in schema de alocare are ca rezultat non-redundanta; o mapare 1-M defineste o baza de date distribuita (fizic).
Cele trei obiective importante ale proiectarii bazei de date in sistemele distribuite sunt:
Separarea fragmentarii si alocarii datelor
Controlul redundantei
Independenta fata de sistemele locale de gestionare a bazelor de date
A se vedea sectiunile "Sisteme Distribuite" si "Replicarea".
Ultimul pas in faza de proiectare este de a produce o structura fizica specific-DBMS pentru fiecare din bazele de date locale si de a defini schema utilizator extern. Intr-un sistem eterogen, schema locala si proiectarea fizica sunt dependente de site.
Metodologia de proiectare logica simplifica abordarea bazelor de date relationale mari, reducand numarul de dependente de date care trebuie analizate. Acest lucru se realizeaza prin inserarea ERM si vizualizarea pasului de integrare in abordarea traditionala a proiectarii. Obiectivul acestor pasi este de a obtine cu acuratete reprezentare a realitatii. Integritatea datelor se pastreaza prin normalizarea tabelelor candidate create cand ERM este transformat intr-un model relational.
Odata ce proiectarea este terminata, poate fi creata baza de date prin implementarea schemei formale utilizind limbajul de definire a datelor (DDL) a unei DBMS. Apoi poate fi utilizat limbajul de manipulare a datelor (DML) pentru a interoga si actualiza baza de date si de asemenea pentru a stabili indecsii si constrangerile cum ar fi cele de integritate referentiala. Cand baza de date incepe operarea, prin monitorizare se va observa daca specificatiile de performanta sunt indeplinite. Daca acestea nu sunt satisfacute trebuie facute modificari pentru a imbunatati performantele.
Tehnicile de modelare generale utilizate in sistemele de baze de date pot fi impartite in trei categorii:
Modele de date si informatii (ex.: Modelul Entitate-Relatie, Modelul Obiect)
Modele de functionalitate (ex.: Modelul Functie)
Modele de integrare a functionalitatilor si datelor (ex.: Modelul Matrice)
Ne vom concentra asupra modelelor de date vs. alte tehnici de modelare.
Obiectivul Modelarii Entitate-Relatie - ERM este de a defini si intelege lucrurile semnificative pentru care trebuie cunoscute sau pastrate informatii, precum si asocierile dintre ele.
Tehnicile utilizate pentru a atinge aceste obiective sunt:
Diagrama Entitate-Relatie - ERD si
suportul, informatii documentate care definesc si descriu complet fiecare entitate si relatiile ei.
ERM incepe prin identificarea datelor necesare pentru a acorda suport functiunilor necesare activitatii.
Specificatiile de date sunt identificate in timpul interviurilor si a altor procese de colectare a datelor si sunt utilizate pentru a stabili o lista de entitati candidate. Entitatile candidate sunt evaluate din punct de vedere al semnificatiei si a regulilor formale, in scopul stabilirii entitatilor reale ce vor fi diagramate si documentate complet.
ERD e dezvoltat si informatiile pastrate pentru fiecare entitate sunt definite si documentate ca atribute.
Fiecare entitate va avea una sau mai multe asocieri cu alte entitati. Acestea sunt diagramizate /documentate ca relatii
Termenii de baza in ERM sunt:
Entitate
Relatie
Atribut
Super-tip
Sub-tip
identificator unic
ENTITATI
Entitatile nu exista izolate. Fiecare va avea cel putin o relatie cu alta entitate (daca nu inseamna ca nu este o entitate).
RELATII
Relatiile definesc reguli care asigura functionalitatea specificata.
Caracteristici:
Optional: obligatoriu/optional,
Conectivitate/Cardinalitate
M-1/1-M/M-M/1-1,
Nume: la fiecare extremitate poate fi citit "trebuie sa fie", "poate sa fie".
Tip: uzual, exclusiv, recursiv
ATRIBUTE
Un atribut are un nume unic cu semnificatie intr-o entitate care se poate repeta intre entitati si care are o singura valoare pentru fiecare instanta a entitatii parinte.
Daca o regula functionala permite unui atribut sa aibe mai mult de o valoare pentru o singura instanta a entitatii, atunci atributul devine o entitate. (e.g. adresa)
Caracteristici:
Optionalitate: obligatoriu/optional
Parte (sau nu) a unui identificator unic - UID.
SUPER-TIPURI/GENERALIZARE si SUB-TIPURI/SPECIALIZARE
Modelarea initiala va fi divergenta si va creste in volum in ceea ce priveste entitatile si relatiile si deci in complexitate. Aceasta poate duce la neintelegeri si erori.
Convergenta este procesul prin care un model poate fi simplificat fara pierderi de definitie.
Procesul de dezvoltare a ERM ar trebui sa fie mai intai divergenta, urmata apoi de convergenta.
Convergenta va reduce numarul de entitati si relatii. In schimb, acest lucru va reduce numarul de functiuni necesare dar cu costul potential al unei mai mari complexitati a functiunilor. In exces, convergenta va duce la pierderi de definitie ale modelului si va reduce gradul de intelegere.
Convergenta necesita de obicei utilizarea de super-tipuri si sub-tipuri.
Reguli
cel putin doua sub-tipuri pentru un super-tip.
setul de sub-tipuri trebuie sa fie comprehensibil
un sub-tip poate avea el insusi sub-tipuri
nu se recomanda mai mult de doua nivele de sub-tipuri datorita complexitatii
sub-tipurile mostenesc atributele si relatiile de la super-tipuri
sub-tipurile valide ar trebuie sa aibe atribute si/sau relatii distincte
sub-tipurile la fel ca toate entitatile trebuie sa fie mutual exclusive.
In Abordarea Orientata Obiect (OOA) sunt incorporate idei noi: ascunderea informatiei intr-un set coerent de reguli pentru structurarea datelor si pentru operatiile cu date.
Termenii de baza in OOA sunt:
Identitate
Clasificare
Polimorfism
Mostenire
In OM clasele (sau tipurile) sunt vizualizate ca o colectie de metode, adica operatiuni pe clase specifice de de obiecte.
OM descrie obiectele individuale din sistem, identitatea, atributele, comportarea si relationarea lor cu alte obiecte. Diagrama obiect este o reprezentare conceptuala a modelului obiect in acelasi fel in care ERD reprezinta un ERM.
ERM specifica numai structura datelor si nu comportarea lor in timp ce OM specifica atributele si operatiile acelei clase de obiecte.
Obiectivul Modelarii Functionale - FM este de a identifica comprehensiv si cu acuratete functiunile activitatii ce trebuie indeplinite in cadrul organizatiei. FM, agreata impreuna cu utilizatorii, reprezinta baza proiectarii modulelor.
Datele au valoare numai daca au o utilizare functionala. ERM trebuie sa fie inrudit indeaproape cu FM.
ERM si FM trebuie facute in paralel de cate ori este posibil.
Esential pentru fazele de proiectare si constructie in dezvoltarea sistemelor de baze de date este informatia referitoare la entitate si utilizarea atributelor pentru fiecare functie, dar in mod special pentru functiile elementare ale activitatii (EBF).
EBF sunt functii care preiau activitatea intr-o anumita stare de consistenta si o aduc in alta sau care nu modifica deloc starea activitatii. 'Starea activitatii' este informatia cunoscuta de activitatea respectiva si reprezentata de catre ERD. Daca un EBF nu poate fi terminat este ca si cum nu a fost inceput.
Pentru entitati, functia utilizata poate fi una sau mai multe din setul CRUD (Creare, Regasire, Actualizare, Stergere).
Pentru atribute functia utilizata va fi din setul: inserare, regasire, actualizare, nulificare.
Obiectivul oricarei matrici este de a defini asocierea/asocierile dintre doua sau mai multe elemente sau clase. Obiectivul oricarei matrici specifice depinde de elementele care sunt in asociere.
In metoda CASE, in faza de analiza, modelarea matriceala - MM este utilizata in principal pentru a verifica alte modele din punct de vedere al acuratetii, completitudinii si logicii.
Tehnicile de modelare matriceala constau in definirea unei clase de elemente pentru randuri si a altei clase pentru coloane. Orice relatie intre un element al randului si unul al coloanei este definita la intersectie fie de un caracter insemnand ca relatia exista sau de unul sau mai multe caractere definind natura relatiei.
Matricea Functie/Entitate
Matricea Functie/Entitate - este utilizata extensiv in faza de analiza a unui proiect de sistem de baze de date. Sunt incluse numai EBF-uri. Aceste EBF sunt listate vertical ca randuri de definitii iar entitatile sunt listate orizontal. La intersectie, utilizarea unei functii de catre o entitate poate fi aratata prin introducerea uneia sau mai multora dintre:
U actualizare
C creare
D stergere
R regasire
Obiectivul este de a asigura ca functia si modelul de date sunt compatibile. Procesul de constructie al matricei va evidentia unde:
EBF se refera la lucruri altele decat entitatile care sunt reprezentate in ERM
Entitatile nu au functii asociate.
Matricea Functie/Entitate poate fi utilizata pentru identificarea:
functiilor care nu utilizeaza nici o informatie
functiilor care utilizeaza informatii identice
entitatilor care nu au semnificatie pentru instantele ce se vor crea
entitatilor care nu au semnificatie pentru instantele ce vor fi sterse
entitatilor in care instantele sunt create si/sau sterse fara alta utilizare
Entitati care nu sunt utilizate de nici o functie.
Exemplu generic:
ENTITATE
FUNCTIE
E2
E3
E4
F1
C
U
D
F2
C/U
F3
D
C
F4
R
R
Dupa cum se observa in exemplul de mai sus, exista o usoara coincidenta a F1 si F2 relativ la entitatea E2 (amandoua o actualizeaza). De asemenea, E4 nu are deloc functii asociate.
Matricea Functie/Atribute
Exista o extensie detaliata a matricei Functie/Entitate. EBF sunt listate vertical si atributele orizontal. La intersectie poate fi aratata utilizarea atributelor de catre functie:
U actualizare
I inserare
N nullificare
R regasire
Matricea Functie/ Atribut poate fi folosita pentru a identifica:
functiile pentru care utilizarea atributului nu este definita
functiile unde nu exista atribut pentru inregistrarea starii modificate in entitatea afectata
functiilor care utilizeaza entitati identice dar atribute diferite
atribute care nu au semnificatie pentru instantele ce se vor insera
atribute care nu au semnificatie pentru instantele ce se vor nulifica
ATRIB
FUNCTIE
A1
A2
A3
A4
F1
R
R
R
I
F2
R
U/N
U/N
F3
R
R
R
R
F4
I
I
R
R
Tabelele bazei de date relationale sufera uneori din cauza unor probleme serioase in ceea ce priveste performanta, integritatea si gestionarea. De exemplu, cand este definita intreaga baza de date ca un tabel mare unic, poate rezulta o mare cantitate de date redundante si cautari indelungate pentru numai cateva randuri. Pot de asemenea rezulta lungi si costisitoare actualizari si stergeri, in particular pot rezulta eliminari de date utile si alte efecte nedorite.
Exemplu (baza de date tabel unic)
Sales
Product_name
Order_no
Cust_name
Cust_addr
Credit
Date
Sales_name
Aspirator
1458
Bachmann
Austin
6
5.5.92
Bloch
Computer
2730
Huang
Mt.Vedere
10
5.6.92
Hanss
Frigider
2460
Stolarchuk
Ann Arbor
8
7.3.92
Phillips
Televizor
519
Honeyman
Detroit
3
9.5.92
Remley
Radio
1986
Antonelli
Chicago
7
9.18.92
Metz
CD-player
1817
Ravishankar
Bombay
8
1.3.93
Basile
Aspirator
1865
Antonelli
Chicago
7
4.18.93
Bloch
Aspirator
1885
Blower
Detroit
8
5.13.93
Bloch
Frigider
1943
Bachmann
Austin
6
6.19.93
Phillips
Televizor
2315
Bachmann
Austin
6
7.15.93
Remley
Sa revedem intai formele normale de baza care au fost bine stabilite in literatura si practica bazei de date relationale.
Nivelul cel mai de baza al tabelelor normalizate este prima forma normala in care fiecare coloana apare o singura data in tabela.
O tabela este in prima stare normala 1NF daca nu exista grupe repetitive de coloane intr-un rand.
Exemplu
Tabela nenormalizata
Report_no
Editor
Dept_no
Dept_name
Dept_addr
Author_id
Author_name
4216
Woolf
15
Design
Argus 1
53
Mantei
5789
Koenig
27
Analysis
Argus 2
26
Fry
Author_addr
Author_id
Author_name
Author_addr
Author_id
Author_name
Cs-tor
44
Bolton
Mathrev
71
Koenig
Folkstone
38
Umar
Prize
71
Koenig
Tabela normalizata (1NF)
RAPORT
Report_no
Editor
Dept_no
Dept_name
Dept_addr
Author_ id
Author_name
Author_addr
4216
Woolf
15
Design
Argus 1
53
Mantei
Cs-tor
4216
Woolf
15
Design
Argus 1
44
Bolton
Mathrev
4216
Woolf
15
Design
Argus 1
71
Koenig
Mathrev
5789
Koenig
27
Analysis
Argus 2
26
Fry
Folkstone
5789
Koenig
27
Analysis
Argus 2
38
Umar
Prize
5789
Koenig
27
Analysis
Argus 2
71
Koenig
Mathrev
Dezavantajul unei tabele de a se afla in 1NF este duplicarea datelor, efectuarea actualizarii si problemele de integritate a actualizarii. Pentru a rezolva acest lucru trebuie introduse alte concepte.
O supercheie este un set de atribute/coloane care identifica in mod unic o instanta/rand intr-o entitate/tabela. Orice subset de atribute al unei superchei care este de asemenea o supercheie si nu e reductibila la o supercheie este denumita cheie candidata.
In exemplul de mai sus o supercheie triviala este o colectie a tuturor atributelor. Presupunand ca un departament are o singura adresa putem conchide ca toate atributele minus dept_addr formeaza din nou o supercheie. Deci ajungem la concluzia ca report_no si author_id determina in mod unic toate celelalte atribute si deci este o supercheie. Totusi nici report_no nici author_id nu pot ele singure sa determine in mod unic un rand si compozitia acestor doua atribute nu poate fi redusa si sa fie in continuare o supercheie. Astfel report_no si author_id devin chei candidate. Din moment ce este singura cheie candidata din tabela, ea devide de asemenea cheie primara.
In cele ce urmeaza vor fi utile dependentele functionale. Proprietatea unuia sau mai multor atribute care determina in mod unic valoarea unuia sau mai multor atribute se numeste dependenta functionala (FD).
In exemplul precedent sa presupunem urmatoarele dependente functionale pentru tabela RAPORT:
RAPORT: report_no editor, dept_no
Dept_no dept_name, dept_addr
Author_id author_name, author_addr
O tabela este in a doua forma normala (2NF) daca si numai daca este in 1NF si fiecare atribut non-cheie este complet dependent de cheia primara. Un atribut se spune ca este complet dependent de cheia primara daca este pe partea dreapta a FD pentru care partea stanga este fie cheia primara fie ceva ce poate fi derivat din cheia primara utilizand tranzitivitatea FD.
Un exemplu de FD tranzitiva in tabela RAPORT este urmatorul:
Report_no dept_no
Dept_no dept_name
Putem deriva FD (report_no dept_name) din moment ce dept_name este dependent tranzitiv de report_no.
Report_no, author_id este singura cheie candidata si deci este cheie primara. Totusi exista o FD (dept_no dept_name, dept_addr) care nu are o componenta a cheii primare in partea stanga, si doua FD (report_no editor, dept_no and author_id author_name, author_addr) care contin o componenta a cheii primare pe partea stanga, dar nu ambele componente. O astfel de tabela RAPORT nu satisface conditia pentru 2NF pentru nici unul dintre FD.
Tabela RAPORT in 1 NF prezinta urmatoarele dezavantaje:
Anomalia de Actualizare - reprezinta o potentiala degradare a performantelor datorita actualizarii redundante. report_no, editor si dept_no sunt duplicate pentru fiecare autor al raportului. Daca editorul raportului se modifica, trebuie actualizate cateva randuri.
Anomalia de Inserare - Daca trebuie adaugat un nou editor la tabela, acest lucru se poate face daca acest editor editeaza un raport deoarece atat numarul raportului cat si numarul editorului trebuie cunoscute pentru a adauga un rand la o tabela (fiind componente ale cheii primare).
Anomalia de Stergere - pot exista efecte nedorite la stergere de natura urmatoare: daca o tabela este stearsa, toate randurile asociate acelui raport trebuie sterse. Aceasta are ca efect stergerea informatiei care asociaza author_id cu author_name si author_addr.
Acestea reprezinta o potentiala pierdere de integritate deoarece singurul mod in care datele pot fi restaurate este de a gasi datele undeva in afara bazei de date si a le insera inapoi in baza de date.
Anomalia de stergere este de departe cea mai serioasa deoarece se pot pierde date ce nu mai pot fi regasite apoi.
Aceste dezavantaje pot fi inlaturate prin transformarea tabelei 1NF in doua sau mai multe tabele 2NF prin utilizarea operatorului projection (proiectie) pe subsetul de atribute al tabelei 1NF.
Proiectia tabelei RAPORT in trei tabele mai mici a pastrat FD-ul si asocierea dintre report_no si author_id care erau importante in tabela originala.
Sunt prezentate datele pentru cele trei tabele (repetitiile sunt sterse)
RAPORT1
Report_no
Editor
Dept_no
Dept_name
Dept_addr
4216
Woolf
15
Design
Argus 1
5789
Koenig
27
Analysis
Argus 2
RAPORT2
Author_id
Author_name
Author_addr
53
Mantei
Cs-tor
44
Bolton
Mathrev
71
Koenig
Mathrev
26
Fry
Folkstone
38
Umar
Prize
71
Koenig
Mathrev
RAPORT3
Report_no
Author_id
4216
53
4216
44
4216
71
5789
26
5789
38
5789
71
FD-urile pentru aceste tabele 2NF sunt:
RAPORT1: report_no editor, dept_no
Dept_no dept_name, dept_addr
RAPORT2: author_id author_name, author_addr
RAPORT3: report_no, author_id este cheie candidata (fara FD).
Totusi, nu toate degradarile de performanta sunt eliminate. Report_no este duplicat pentru fiecare autor si stergerea unui raport necesita actualizarea la doua tabele (RAPORT1 si RAPORT3) in loc de una. Totusi acestea sunt probleme minore in comparatie cu cele din tabela 1NF RAPORT.
Tabelele 2NF reprezinta o imbunatatire semnificativa fata de tabelele 1NF; ele sufera in continuare de aceleasi tipuri de anomalii ca si tabelele 1NF, dar din diferite motive asociate cu dependentele tranzitive. Daca o dependenta functionala tranzitiva exista intr-o tabela, inseamna ca doua lucruri separate sunt reprezentate in acea tabela, unul pentru fiecare dependenta functionala implicand o parte stanga diferita.
RAPORT11
Report_no
Editor
Dept_no
4216
Woolf
15
5789
Koenig
27
REPORT12
Dept_no
Dept_name
Dept_addr
15
Design
Argus 1
27
Analysis
Argus 2
RAPORT2
Author_id
Author_name
Author_addr
53
Mantei
Cs-tor
44
Bolton
Mathrev
71
Koenig
Mathrev
26
Fry
Folkstone
38
Umar
Prize
71
Koenig
Mathrev
RAPORT3
Report_no
Author_id
4216
53
4216
44
4216
71
5789
26
5789
38
5789
71
O tabela este in a treia forma normala (3NF) daca si numai daca pentru fiecare dependenta ne-triviala (X A, unde X si A sunt atribute simple sau compozite) una din urmatoarele doua conditii trebuie indeplinite: fie X este o supercheie fie A este membru al unei chei candidate. Daca A este membru al unei chei candidate atunci A se numeste atribut prim.
In exemplul precedent dupa proiectia tabelei RAPORT1 in tabelele REPORT 11 si REPORT12 pentru a elimina dependenta tranzitiva report_no dept_no dept_name, dept_addr avem urmatoarele tabele 3NF si dependentele lor functionale:
RAPORT11: report_no editor, dept_no
RAPORT12: dept_no dept_name, dept_addr
RAPORT2: author_id author_name, author_addr
RAPORT3: report_no,author_id este o cheie candidata (fara FD)
A treia forma normala care elimina majoritatea anomaliilor cunoscute astazi in bazele de date este standardul cel mai obisnuit pentru normalizare in bazele de date comerciale si utilitarele CASE. Cele cateva anomalii ramase pot fi eliminate prin forma normala Boyce-Codd si formele normale superioare. Forma normala Boyce-Codd este considerata a fi o puternica variatie a 3NF.
A tabela este in forma normala Boyce-Codd (BCNF) daca pentru fiecare dependenta functionala ne-triviala X A, X este supercheie.
BCNF este o forma de normalizare mai puternica decat 3NF deoarece elimina a doua conditie pentru 3NF, ce permite extremitatii drepte a FD sa fie un prim atribut. Astfel fiecare parte stanga a FD dintr-o tabela trebuie sa fie o supercheie. Fiecare tabela care este BCNF este de asemenea si 3NF, 2NF si 1NF prin definitiile precedente.
Urmatorul exemplu prezinta o tabela 3NF care nu este BCNF. Astfel de tabele au anomalii de stergere similare cu cele din formele normale inferioare.
Asertiunea 1: Pentru o echipa data, fiecare salariat este condus de un singur sef. O echipa poate fi condusa de mai multi sefi.
Emp_name, team_name leader_name
Asertiunea 2: Fiecare sef conduce numai o echipa.
Leader_name team_name
Echipa
Emp_name
Team_name
Leader_name
Sutton
Hawks
Wei
Sutton
Condors
Bachmann
Niven
Hawks
Wei
Niven
Eagles
Makowski
Wilson
Eagles
DeSmith
Aceasta tabela este 3NF cu o cheie candidata compozita emp_name, team_name.
Tabela echipa are urmatoarea anomalie de stergere: daca Sutton elimina echipa Condors atunci nu avem nici o inregistrare a Bachmann conducand echipa Condors. S-a aratat ca acest tip de anomalie nu poate avea o decompozitie fara pierderi si pastreaza toate FD-urile.
O decompozitie fara pierderi necesita ca la descompunerea tabelei in doua tabele similare mai mici prin proiectia tabelei originale asupra a doua subseturi ale unei scheme, care coincid partial, concatenarea (join) naturala a acestor tabele va rezulta in tabela originala fara alte randuri suplimentare nedorite. Cel mai simplu mod de a evita anomalia de stergere pentru acest tip de situatie este de a crea o tabela separata pentru fiecare din cele doua asertiuni.
Echipa1
Emp_name
Leader_name
Sutton
Wei
Sutton
Bachmann
Niven
Wei
Niven
Makowski
Wilson
DeSmith
Echipa2
Team_name
Leader_name
Hawks
Wei
Condors
Bachmann
Eagles
Makowski
Eagles
DeSmith
Aceste doua tabele sunt suficient de redundante astfel incat sa se evite anomalia de stergere. Acesta descompunere este fara pierderi si pastreaza FD-urile, dar degradeaza performantele de actualizare datorita redundantei si necesitatii unui spatiu suplimentar de stocare.
Modelul relational are trei aspecte majore:
Obiectele bazei de date - obiecte bine-definite (cum ar fi tabele, vederi, indecsii, s.a.m.d.) care stocheaza sau acceseaza datele unei baze de date. Obiectele bazei de date si datele continute de ele pot fi manipulate prin operatii.
Operatii - actiuni clar definite care permit utilizatorilor sa manipuleze datele si obiectele bazei de date. Operatiile asupra unei baze de date trebuie sa adere la un set predefinit de reguli de integritate.
Reguli de integritate - legile care guverneaza operatiile permise asupra datelor si obiectelor bazei de date.
SQL este limbajul structurat de interogare pentru accesarea bazelor de date relationale pentru:
Interogarea datelor
Definirea obiectelor bazei de date (Limbajul de Definire a Datelor - DDL)
Manipularea obiectelor bazei de date (Limbajul de Manipulare a Datelor - DML)
Administrarea drepturilor de acces
Comentariu: PL/SQL este un limbaj Oracle procedural pentru scrierea logicii aplicatiei si pentru manipularea datelor in afara bazei de date.
SQL*Plus este produsul Oracle in care pot fi utilizate limbajele SQL si PL/SQL.
Comanda SQL select este baza tuturor interogarilor bazei de date.
Comenzile DDL de baza ale SQL pentru structuri date (tabele, indexi, vederi) sunt:
create - defineste structura date
alter - modifica structura date
drop - sterge structura date.
Comenzile DML de baza ale SQL sunt:
Insert - introduce noi randuri
Update - modifica randurile existente
Delete - sterge randurile existente
Comenzile SQL utilizate penrtru a acorda sau restrictiona accesul la diferite obiecte ale bazei de date sunt:
Grant
revoke
A se vedea cursul (3210) - "Limbajul SQL".
O vedere in SQL este o tabela (virtuala) denumita, derivata care are datele derivate din tabele de baza, tabelele actuale definite de comanda "create table". In timp ce definitiile vederii pot fi stocate in baza de date, vederile (tabelele derivate) nu sunt stocate, ci derivate la momentul executiei cand vederea este invocata de o interogare ce utilizeaza comanda SQL select. Persoana care interogheaza vederea o trateaza ca si cum ar fi o tabela (storata) actuala, netinand cont de diferentele dintre vedere si tabela de baza.
Vederile sunt utile in mai multe feluri. Mai intai, ele permit ca interogari complexe sa fie stabilite dinainte intr-o vedere, iar utilizatorul novice de SQL trebuie sa faca o simpla interogare a vederii. Aceasta interogare simpla invoca la randul ei interogari mai complexe definite de vedere. Astfel ne-programatorii pot utiliza SQL la adevarata lui putere fara a avea nevoie sa creeze interogari complexe.
In al doilea rand, vederile asigura o mai mare securitate unei baze de date deoarece DBA poate asigna diferite vederi la diversi utilizatori si poate controla ce vede fiecare utilizator in baza de date.
In al treilea rand, vederile asigura o semnificatie mai mare a independentei datelor - adica, chiar daca tabelele de baza pot fi modificate prin adaugare, stergere, sau modificarea coloanelor, interogarea vederii poate sa nu necesite o modificare. In timp ce definitia vederii poate necesita o modificare, asta este treaba DBA, si nu a persoanei care interogheaza vederea.
Este important ca datele sa adere la un set predefinit de reguli, asa cum s-a stabilit de catre administrator sau de catre dezvoltatorul de aplicatie. Ca exemplu de integritate a datelor, sa consideram tabelele EMP si DEPT si regulile functionale pentru informatiile din fiecare tabela, asa cum se arata in Figura 1.
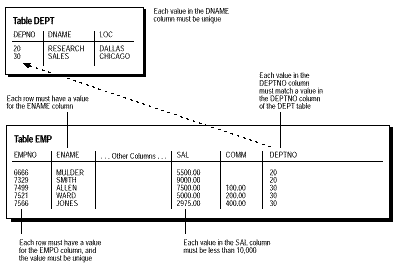
Fig. 1
De notat ca anumite coloane ale fiecarei tabele au reguli specifice care constrang datele continute in ele.
Urmatoarele tipuri de reguli se aplica tabelelor si permit obtinerea diferitelor tipuri de integritate a datelor.
Nuluri - O regula definita pe o singura coloana care permite sau nu inserarea sau actualizarea randurilor care contin un nul pe o coloana.
Valori unice ale coloanei - O regula definita pe o coloana (sau set de coloane) ce permite numai inserarea sau actualizarea unui rand continand o valoare unica a coloanei (sau set de coloane).
Valori Cheie Primara - O regula definita pe o coloana (sau set de coloane) astfel incat fiecare rand din tabela poate fi identificat in mod unic de catre valorile din coloana (sau set de coloane).
Integritate Referentiala - O regula definita pe o coloana (sau set de de coloane) intr-o tabela ce permite inserarea sau actualizarea unui rand numai daca valoarea pentru coloana sau set de coloane (valoarea dependenta) se potriveste cu o valoare intr-o coloana a unei tabele inrudite (valoarea referita). Integritatea referentiala include de asemenea regulile care dicteaza ce tip de manipulare a datelor este permisa pentru valorile referite si cum vor afecta aceste actiuni valorile dependente. Regulile asociate cu integritatea referentiala includ:
Restrictionare - O regula de integritate referentiala care nu permite actualizarea sau stergerea datelor referite.
Setare la Nul - Cand datele referite sunt actualizate sau sterse, toate datele dependente asociate sunt setate la NUL.
Setare pe Implicit - Cand datele referite sunt actualizate sau sterse, toate datele dependente asociate sunt setate la o valoare implicita.
Cascada - Cand datele referite sunt actualizate, toate datele dependente asociate sunt actualizate corespunzator; cand un rand referit este sters, toate randurile dependente asociate sunt sterse.
Verificarea Complexa a Integritatii - O regule definita de utilizator pentru o coloana (sau set de coloane) care permite sau restrictioneaza inserarea, actualizarea, sau stergerea unui rand pe baza valorii pe care o contine pentru coloana (sau set de coloane).
Oracle permite definirea fiecarui tip de reguli de integritate a datelor definite in sectiunea precedenta. Cele mai multe dintre aceste reguli sunt definite cu usurinta utilizand constrangerile de integritate.
O constrangere de integritate este o metoda declarativa de definire a regulii pentru o coloana a tabelei. Oracle suporta urmatoarele constrangeri de integritate:
NOT NULL pentru reguli asociate cu nul intr-o coloana
CHEIE UNICA pentru regula asociata cu valori unice ale coloanei.
CHEIE PRIMARA pentru regula asociata cu valorile primare de identificare
CHEIE STRAINA pentru regulile asociate cu integritatea referentiala. Oracle suporta de obicei utilizarea contrangerii de integritate CHEIE STRAINA pentru a defini actiunile de integritate referentiala, incluzand
actualizare si stergere RESTRICT
stergere CASCADE
CHECK pentru reguli de integritate complexe
Alte actiuni de integritate referentiale neincluse in aceasta lista pot fi definite utilizand triggerii bazei de date.
Oracle va permite de asemenea sa obtineti reguli de integritate cu o abordare non-declarativa utilizand triggerii bazei de date (proceduri storate ale bazei de date invocate automat la operatiile de inserare, actualizare sau stergere). Chiar daca va permit sa definiti si sa obtineti orice tip de regula de integritate, este recomandabil sa utilizati triggerii bazei de date numai in urmatoarele situatii:
cand o regula de integritate referentiala necesara nu poate fi impusa utilizand constrangerile de integritate listate mai sus: actualizare CASCADE, actualizare si stergere SET NULL, actualizare si stergere SET DEFAULT
cand tabelele copil si parinte sunt pe noduri diferite ale unei baze de date distribuite
reguli functionale complexe nedefinibile prin utilizarea constrangerilor de integritate
Oracle utilizeaza constrangerile de integritate pentru a preveni intrarile de date invalide in tabelele de baza ale bazei de date. Puteti defini constrangerile de integritate pentru a impune reguli functionale asociate cu informatiile din baza de date. Daca vreunul din rezultatele executarii declaratiei DML violeaza o constrangere de integritate, Oracle deruleaza declaratia inapoi si returneaza un mesaj de eroare.
Avantajele constrangerilor de integritate fata de alte alternative.
Usurinta Declaratiei
Deoarece dvs. definiti constrangeri de integritate utilizand comenzile SQL, cand definiti sau modificati o tabela, nu este necesara programarea. Astfel, ele sunt usor de scris, elimina erorile de programare si Oracle le controleaza functionalitatea.
Reguli centralizate
Constrangerile de integritate sunt definite pentru tabele (nu o aplicatie) si stocate in dictionarul de date. Astfel, datele introduse de orice aplicatie trebuie sa adere la aceleasi constrangeri de integritate asociate unei tabele. Prin mutarea regulilor de functionare de la codul aplicatiei la constrangerile de integritate centralizate, tabelele unei aplicatii de baze de date contin garantat date valide, indiferent ce baza de date manipuleaza informatia.
Productivitatea maxima de dezvoltare a aplicatiei
Daca o regula de functionare este impusa de o constrangere de integritate, administratorul trebuie doar sa modifice acea constrangere de integritate si toate aplicatiile adera automat la constrangerea modificata.
Performanta superioara
Deoarece semantica declaratiilor constrangerii de integritate este clar definita, optimizarile de performanta sunt implementate pentru fiecare regula declarativa specifica.
Flexibilitatea Incarcarii Datelor si Identificarea Violarilor de Integritate
Constrangerile de integritate pot fi temporar dezactivate astfel incat mari cantitati de date sa poata fi incarcate fara verificarea acestor constrangeri. Cand incarcarea datelor este completa, puteti sa activati constrangerile de integritate cu usurinta, si puteti raporta automat orice randuri noi care violeaza constrangerile de integritate intr-o tabela separata.
Constrangerile de integritate pe care le puteti utiliza pentru a impune restrictii la introducerea valorilor coloanei pot fi de urmatoarele tipuri:
constrangeri NOT NULL
constrangeri CHEIE UNICA
constrangeri CHEIE PRIMARA
constrangeri (referentiale) CHEIE STRAINA
constrangeri CHECK (verificare)
Implicit, toate coloanele dintr-o tabela permit valori nule (absenta valorii). O constrangere NOT NULL necesita ca valori lipsa sa nu fie permise intr-o coloana a tabelei. De exemplu, puteti defini o constrangere NOT NULL pentru a cere introducerea unei valori in coloana ENAME pentru fiecare rand al tabelei EMP.
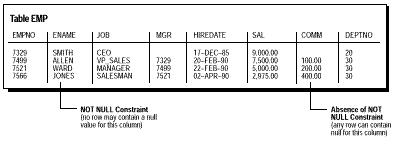
Fig. 2
O constrangere de integritate cheie UNICA inseamna sa nu existe doua randuri ale unei tabele cu valori duplicate intr-o coloana specificata sau un set de coloane. De exemplu, sa consideram tabela DEPT din figura 3. O constrangere tip cheie unica este definita in coloana DNAME pentru a nu permite randuri cu nume de departamente duplicat.
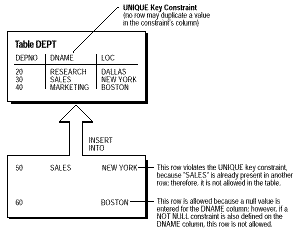
Fig. 3
Coloana (sau setul de coloane) inclusa in definirea constrangerii cheie unica este numita cheie unica. Termenul de "cheie unica" este adesea incorect utilizat ca sinonim pentru termenul "constrangere cheie UNICA" sau "index UNIC"; totusi, notati ca termenul "cheie" se refera numai la lista coloanelor utilizate in definirea constrangerii de integritate. Daca constrangerea Cheie UNICA este continuta de mai mult de o coloana, acel grup de coloane se numeste cheie unica compozita. De exemplu, in figura de mai jos, tabela CUSTOMER are o constrangere cheie unica definita pe cheia unica compozita: coloanele AREA si PHONE.
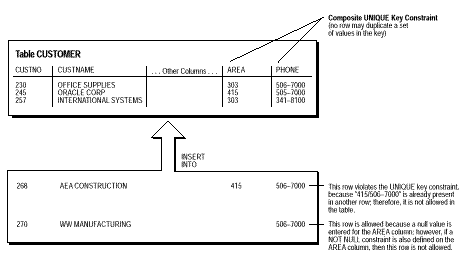
Fig. 4
Aceasta constrangere CHEIE UNICA va permite sa introduceti un cod postal si un numar de telefon, dar combinatia cod postal si numar de telefon nu poate fi duplicata in tabela. Acest lucru elimina duplicarile neintentionate ale numarului de telefon.
Observati in exemplele din sectiunea anterioara cum constrangerile Cheie UNICA permit introducerea de nuluri cu exceptia cazului in care definiti de asemenea constrangeri NOT NULL pentru aceeasi coloana. De fapt, orice numar de randuri poate include nuluri pentru coloanele care nu au constrangeri NOT NULL deoarece nulurile nu sunt considerate la fel. Un nul intr-o coloana (sau in toate coloanele unei chei unice compozite) satisface intotdeauna o constrangere cheie unica. Se obisnuieste sa se defineasca chei unice pe coloane cu contrangeri de integritate NOT NULL. Aceasta combinatie forteaza utilizatorul sa introduca valori in cheia unica; aceasta combinatie de reguli de integritate a datelor elimina posibilitatea ca noi date ale randului sa fie in conflict cu datele existente ale randului.
Nota Din cauza mecanismului de cautare pentru constrangerile cheie UNICA pe mai mult de o coloana, nu puteti avea valori identice in coloanele non-null ale unei constrangeri cheie unica compozita partial nula.
Fiecare tabela din baza de date poate avea cel mult o constrangere CHEIE PRIMARA. Valorile intr-un grup de una sau mai multe coloane subiect al acestei constrangeri constituie unicul identificator al randului. Fiecare rand este denumit de valorile cheilor sale primare. Implementarea Oracle a constrangerii de integritate CHEIE PRIMARA garanteaza ca amandoua dintre propozitiile urmatoare sunt adevarate:
Nu exista doua randuri ale tabelei care sa aibe valori duplicate in coloana specificata sau in setul de coloane.
Coloanele cheie primara nu permit nuluri (adica, o valoare trebuie sa existe pentru coloanele cheie primara in fiecare rand).
Coloana (sau setul de coloane) care include in definitia unei tabele constrangeri de integritate CHEIE PRIMARA este numita cheie primara. Cu toate ca nu e necesar, fiecare tabela ar trebui sa aibe o cheie primara astfel incat:
fiecare rand din tabela sa poata fi identifica in mod unic
nu exista randuri duplicat in tabela
Figura 5-1 ilustreaza o constrangere CHEIE PRIMARA in tabela DEPT si exemple de randuri pe care constrangerea nu le permite sa intre in tabela.
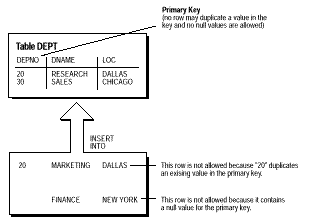
Fig. 5-1
Deoarece tabelele unei baze de date relationale pot fi inrudite prin coloane comune, regulile care guverneaza relatiile dintre coloane trebuie sa fie mentinute. Regulile de integritate referentiale garanteaza ca aceste relatii se pastreaza. Exista mai multi termeni asociati cu constrangerile de integritate referentiale:
Cheie straina - Coloana sau setul de coloane incluse la definitia unei constrangeri de integritate referentiale care refera o cheie referita (a se vedea in continuare).
Cheie Referita - Cheia unica sau cheia primara a aceleiasi tabele sau a unei tabele diferite care este referita de o cheie straina.
Tabela Dependenta sau Copil - este tabela care include cheia straina. Deci este tabela care e dependenta de valorile prezentate in cheia referita unica sau primara.
Tabela Referita sau Parinte - este tabela care e referita de cheia straina a tabelei copil. Cheia referita a acestei tabele cea care determina daca sunt permise insertii sau actualizari specifice in tabela copil.
O constrangere de integritate referentiala necesita ca pentru fiecare rand al tabelei, valoarea din cheia straina sa se potriveasca cu valoarea in cheia parinte.
Figura 5-2 arata o cheie straina definita in coloana DEPTNO a tabelei EMP. Ea garanteaza ca fiecare valoare in aceasta coloana trebuie sa se potriveasca cu o valoare din cheia primara a tabelei DEPT (coloana DEPTNO). Astfel, nu pot exista numere eronate de departament in coloana DEPTNO a tabelei EMP. Cheile straine pot contine coloane multiple. Totusi, o cheie straina compozita trebuie sa refere o cheie primara compozita sau unica cu acelasi numar de coloane si tipuri de date. Deoarece cheile primare compoazite si unice sunt limitate la 16 coloane, o cheie compozita straina este de asemenea limitata la 16 coloane.
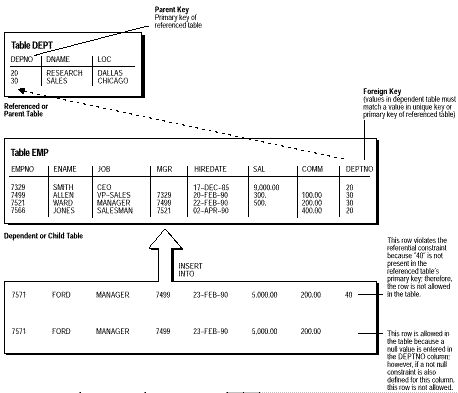
Fig.5-2
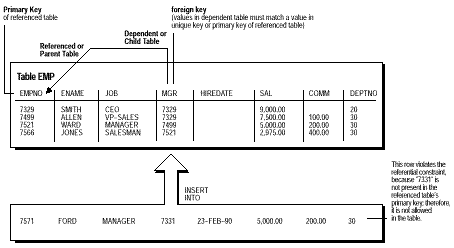 |
Un alt tip de constrangere referentiala de integritate, aratat in figura 5-7, este constrangerea de integritate auto-referentiala. Acest tip de cheie straina se refera la o cheie parinte a aceleiasi tabele. In exemplul de mai jos, se defineste constrangerea de integritate referentiala astfel incat fiecare valoarea din coloana MGR a tabelei EMP sa corespunda cu o valoare care exista in coloana EMPNO a aceleiasi tabele (adica, fiecare director trebuie de asemenea sa fie si salariat). Aceasta constrangere de integritate elimina posibilitatea existentei numerelor eronate de salariati in coloana MGR.
Fig.5-7
Modelul relational permite cheilor straine sa fie o valoare a cheii primare sau unice referite , sau un nul.
Constrangerile de integritate referentiale specifica de asemenea actiunile particulare ce sunt efectuate asupra randurilor dependente intr-o tabela copil daca o valoare a cheii parinte referite este modificata. Actiunile referentiale suportate de constrangerea de integritate CHEIE STRAINA includ UPDATE (actualizare) si DELETE RESTRICT (restrictie la stergere), si DELETE CASCADE (stergere in cascada).
Restrictie la Actualizare si Stergere Actiunea de restrictionare specifica ca valorile cheii referite nu pot fi actualizate sau sterse daca datele rezultate violeaza o constrangere de integritate referentiala.
Delete Cascade Actiunea specifica ca daca randurile continand valori ale cheii referite sunt sterse, toate randurile din tabela copil cu valori ale cheii straine sunt de asemenea sterse.
O constrangere de integritate CHECK pe o coloana sau un set de coloane necesita ca o conditie specificata sa fie adevarata sau necunoscuta pentru fiecare rand al tabelei. Daca se emite o propozitie DML astfel incat conditia constrangerii sa o evalueze ca falsa, propozitia este derulata inapoi.
Sistemele de baze de date multi-user, cum este Oracle, include proprietati de securitate care controleaza modul in care baza de date este accesata si utilizata. De exemplu, mecanismele de securitate efectueaza urmatoarele:
previn accesul neautorizat la baza de date
previn accesul neautorizat la obiectele schemei
controleaza utilizarea discului
controleaza utilizarea resurselor sistemului (cum ar fi timpul CPU)
auditeaza actiunile utilizatorului.
Fiecarui utilizator al bazei de date ii este asociata o schema cu acelasi nume. O schema este o colectie logica de obiecte ale bazei de date (tabele, vederi, secvente, indecsi, clusteri, proceduri, functii, pachete, conexiuni ale bazei de date). Implicit, fiecare utilizator al bazei de date creeaza si are acces la toate obiectele din schema corespunzatoare.
Securitatea bazei de date poate fi clasificata in doua categorii distincte: securitatea sistemului si securitatea datelor.
Securitatea Sistemului - Securitatea sistemului include mecanismele ce controleaza accesul si utilizarea bazei de date la nivelul sistemului. De exemplu, securitatea sistemului include:
combinatii nume utilizator valid/parola
spatiul pe disc disponibil pentru obiectele unui utilizator
limitele de resurse pentru un utilizator.
Mecanismele de securitate ale sistemului verifica:
daca un utilizator este autorizat sa se conecteze la baza de date
daca supravegherea bazei de date este activa
ce operatiuni pot fi executate de catre un utilizator asupra sistemului.
Securitatea datelor - Securitatea datelor include mecanismele ce controleaza accesul si utilizarea bazei de date la nivelul obiectului. De exemplu, securitatea datelor include
ce utilizatori au acces la un obiect specific al schemei si tipurile specifice de actiuni permise pentru fiecare utilizator al obiectului (de exemplu, utilizatorul SCOTT poate face un SELECT si INSERT dar nu DELETE utilizand tabela EMP)
actiunile, daca exista, ce sunt auditate pentru fiecare obiect al schemei.
Oracle RDBMS permite controlul accesului, ceea ce inseamna restrictionarea accesului la informatii pe baza de privilegii. Privilegiul corespunzator trebuie asignat unui utilizator pentru ca acesta sa acceseze un obiect. Oracle gestioneaza securitatea bazei de date utilizand mai multe mecanisme de securitate diferite:
1. utilizatori si scheme ale bazei de date
2. privilegii
3. roluri
4. Setare stocare si cote
5. limitari de resurse
6. auditare
Fiecare baza de date Oracle are o lista de nume de utilizatori. Pentru a accesa o aplicatie de baza de date, utilizatorul trebuie sa utilizeze o aplicatie de baze de date si sa incerce sa se conecteze cu un nume valid de utilizator. Fiecare nume de utilizator are o parola asociata pentru a preveni accesul neautorizat.
Privilegiul reprezinta dreptul de a executa un tip particular de propozitii SQL. Cateva exemple de privilegii:
dreptul de conectare la baza de date (crearea unei sesiuni)
dreptul de a crea o tabela in schema
dreptul de a selecta randuri din tabela altcuiva
dreptul de a executa o procedura storata a altcuiva.
Privilegiile unei baze de date Oracle pot fi impartite in doua categorii distincte: privilegii de sistem si privilegii de obiect.
Privilegii de sistem - permit utilizatorilor sa efectueze o actiune extinsa asupra sistemului sau o actiune particulara asupra unui tip particular de obiect.
Privilegii de obiect - permit utilizatorului sa efectueze o actiune particulara asupra unui obiect specific.
Privilegiile sunt garantate utilizatorilor astfel incat acestia sa poata accesa si modifica datele din baza de date. Un utilizator poate primi un privilegiu in doua moduri diferite:
Privilegii ce se pot acorda explicit utilizatorilor.
Privilegii ce se pot acorda rolurilor (un anumit grup de privilegii), si apoi rolul poate fi acordat unuia sau mai multor utilizatori.
Oracle asigura o gestionare usoara si controlata a privilegiilor prin intermediul rolurilor. Rolurile sunt grupe denumite de privilegii inrudite care sunt acordate utilizatorilor sau altor roluri. Urmatoarele proprietati ale rolurilor permit gestionarea cu usurinta a privilegiilor:
acordarea de privilegii reduse - Mai degraba decat sa acorde acelasi set de privilegii unui grup de utilizatori inruditi, un administrator al bazei de date poate acorda privilegii pentru un grup de utilizatori inruditi carora li se acorda un rol. Apoi administratorul bazei de date poate acorda rolul fiecarui membru al grupului.
gestionarea dinamica a privilegiilor - Cand privilegiile unui grup trebuie modificate, nu e necesara decat modificarea privilegiilor unui rol. Domeniile de securitate pentru toti utilizatorii acordate rolului rolului grupului reflecta automat modificarile facute asupra rolului.
disponibilitatea selectiva a privilegiilor - Rolurile acordate unui utilizator pot fi activate sau dezactivate selectiv. Acest lucru permite controlul specific al privilegiilor unui utilizator intr-o situatie data.
alertarea aplicatiei - O aplicatie de baza de date poate fi proiectata astfel incat sa activeze sau dezactiveze automat rolurile selective cand un utilizator incearca sa utilizezeaplicatia.
Oracle furnizeaza mijloace pentru derectionarea si limitarea utilizarii spatiului pe disc alocat unei baze date de catre utilizator, incluzand tabela de spatiu implicita, tabela temporara de spatiu si cota de spatiu. A se vedea cursul (70670) "Administrare Oracle 7 pe Unix".
Tabela de spatiu implicita - Fiecare utilizator este asociat cu o tabela implicita de spatiu. Cand un utilizator creaza o tabela, index sau cluster si nu este specificata nici o tabela de spatiu pentru a contine in mod fizic obiectul, este utilizata tabela implicita de spatiu daca utilizatorul are privilegiul dea crea obiectul.
Tabela de spatiu temporara - Fiecare utilizator are o tabela temporara de spatiu. Cand utilizatorul executa o propozitie SQL care necesita crearea de segmente temporare (cum ar fi crearea unui indecs), este utilizata tabela temporara de spatiu a utilizatorului.
Cota spatiu - Oracle poate limita cantitatea colectiva de spatiu pe disc disponibila pentru obiectele dintr-o schema. Cota (limitele de spatiu) poate fi setata pentru fiecare tabela de spatiu disponibila pentru un utilizator.
Fiecarui utilizator ii este asignat un profil care specifica limitarile pe resursele de sistem disponibile utilizatorului, incluzand
numarul de sesiuni concurente pe care le poate stabili utilizatorul
timpul de procesare CPU
disponibil pentru sesiunea utilizatorului
disponibil pentru o singura apelare a Oracle efectuata printr-o declaratie SQL
cantitatea de I/O logic
cantitatea de timp inactiv permisa pentru sesiunea utilizatorului
timpul de conectare permis pentru sesiunea utilizatorului.
Oracle permite auditarea selectiva (monitorizarea inregistrarilor) a utilizatorului pentru a ajuta la investigarea suspiciunilor referitoare la utilizarea bazei de date. Auditarea poate fi efectuata la trei nivele diferite: auditarea declaratiei, auditarea privilegiului si auditarea obiectului.
auditarea declaratiei - reprezinta auditarea declaratiillor SQL specifice fara a avea legatura cu obiectele specifice.
auditarea privilegiului - reprezinta auditarea modului de utilizare a puternicelor privilegii de sistem fara legatura cu obiectele specifice. Aceasta auditare poate fi facuta pentru toti utilizatorii sau numai pentru anumiti utilizatori.
auditarea obiectului - reprezinta auditarea accesului la obiectele specifice ale schemei, fara legatura cu utilizatorul.Aceasta auditare monitorizeaza declaratiile permise de privilegiile de obiect , cum ar fi SELECT sau DELETEintr-o tabela data.
Modelul client-server este un raspuns la limitarile prezentate de traditionalul model mainframe client-gazda, in care un singur mainframe furnizeaza accesul la date la mai multe terminale. Modelul client-server este de asemenea un raspuns la modelul LAN, in care mai multe sisteme izolate acceseaza un server de fisiere care nu asigura nici o putere de procesare.
Arhitectura client-server permite integrarea datelor si serviciilor si permite izolarea clientilor din complexitati, cum ar fi protocoalele de comunicare. Simplicitatea arhitecturii client-server permite clientilor sa faca cereri care sunt transmise serverului corespunzator. Aceste cereri sunt facute sub forma unor tranzactii.
Tranzactiile client sunt adeseori proceduri si functii SQL sau PL/SQL care acceseaza individual bazele de date si serviciile.
Client-server architecture is basic for distributed systems.
Un sistem distribuit este un sistem in care atat datele cat si procesarea tranzactiei sunt impartite intre unul sau mai multe computere conectate la o retea, fiecare computer avand un rol specific in cadrul sistemului.
Replicarea face ca intr-un sistem distribuit datele intr-un loc din sistem sa reflecte modificarile efectuate in orice parte a sistemului
Componentele Modelului Client-Server:
clientul
serverul
reteaua
Clientul reprezinta masina (statie de lucru sau PC) care ruleaza aplicatiile front-end. El interactioneaza cu utilizatorul prin intermediul tastaturii, monitorului si mouse-ului. Clientul se refera de asemenea si la procesul client ce ruleaza pe masina client.
Clientul nu are responsabilitati directe referitoare la accesul datelor. El cere efectuarea unor procese din partea serverului si afiseaza datele gestionate de server.
Astfel, statia de lucru client poate fi optimizata pentru aceasta activitate. De exemplu, ea poate sa nu necesite un disc de capacitate mare sau poate beneficia de capabilitati grafice.
Serverul este masina pe care ruleaza Oracle7 si care gestioneaza functiunile necesare pentru accesul concurent la date. Este deseori referit sub numele de back-end. Serverul se refera de asemenea la procesul care ruleaza pe masina server.
Serverul primeste si proceseaza propozitii SQL si PL/SQL provenite din aplicatii client. Serverul poate de asemenea sa fie optimizat. De exemplu, poate avea o capacitate mare a discului si procesor rapid, etc.
Reteaua permite accesul la date de la distanta prin comunicatia client-server si server-server. Produsele Oracle Network permit bazelor de date si aplicatiilor sa stea pe masini diferite cu sisteme de operare diferite in timp ce comunica ca aplicatii de acelasi fel.
Oracle Server poate fi configurat in trei moduri ca:
Proces Dedicat Server Procesul separat al serverului creat pentru fiecare proces utilizator este denumit proces dedicat server (denumit in trecut "proces in umbra") deoarece acest proces actioneaza numai in numele procesului asociat user. In aceasta configuratie (numita uneori two-task), fiecare proces utilizator conectat la Oracle are dedicat un proces server corespunzator.
Proces combinat User/Server In aceasta configuratie, aplicatia de baze de date si codul Oracle Server ruleaza toate in acelasi proces, denumit proces user.
Aceasta configuratie Oracle (numita uneori single-task) este fezabila numai in sistemele de operare care pot mentine o separare intre aplicatia de baze de date si codul Oracle intr-un singur proces (cum ar fi pe sistemul de operare VAX VMS). Aceasta separare este necesara pentru integritatea datelor si confidentialitate. Unele sisteme de operare, cum ar fi UNIX, nu pot asigura separarea, deci ele trebuie sa aibe procese separate care sa ruleze codul aplicatie si codul server astfel incat sa previna erorile.
Server Multi-Threaded Configuratia multi-threaded server (MTS) (sau "server comun") permite mai multor procese user sa imparta intre ele foarte putine procese server.
Intr-o configuratie server multi-threaded, procesele client se conecteaza la un proces de ascultare SQL*Net ce furnizeaza unui client adresa de retea a unui proces dispatcher. Clientul se conecteaza apoi la acest proces dispatcher. Cererile de servicii din partea clientului sunt plasate intr-o coada unde asteapta urmatorul proces server disponibil.
Un sistem de baze de date client-server este un subset al modelului client-server. masina pe care rezida baza de date este serverul de baza de date. De obicei, baza de date pastreaza de asemenea proceduri storate, alertari de eveniment si triggeri. Ea furnizeaza de asemenea servicii, cum ar fi blocare la nivelul randului, securitate, logare, restaurare, gestionarea concurentei, printre altele. Alte tipuri de servere include servere de fisiere, servere de posta electronica, si servere de nume.
O aplicatie front-end interogheaza o baza de date gazda sau bazata pe server si extrage informatii pentru utilizarea lor de catre scriitoarele de rapoarte, foi de calcul, s.a.m.d. De asemenea poate asigura procesarea protocolului si are acces la resursele bazate pe server.
Functiiile aplicatiilor client au mai multe fatete:
interogarea datelor
scriere rapoarte
aplicatii in limbaje de generatia 3 sau 4 (3GL/4GL)
procesare tranzactii
dezvoltare aplicatii
CASE
suport de decizie.
Desi un sistem client-server poate consta intr-un proces server si un proces client care sa existe pe aceeasi masina, noi presupunem ca sistemul client-server tipic consta intr-o masina client si o masina server.
Sistemele client-server nu pot functiona fara comunicatie. Proiectarea oricarui sistem client-server necesita cunoasterea si abilitatea de a implementa reteaua potrivita utilizand SQL*Net, Oracle Names si alte produse de retea.
Cea mai simpla conexiune de retea, client singur la server singur, necesita un singur protocol, furnizat de obicei de sistemul de operare gazda. DECnet, TCP/IP, LU6.2, si ASYNC sunt cateva exemple.
Protocoalele de comunicatie definesc modul in care o retea transmite si primeste date. Intr-un mediu de retea, Oracle Server comunica cu statiile de lucru client si alte Servere Oracle utilizand SQL*Net. SQL*Net suporta comunicatii pe toate protocolalele importante de retea, incepand cu cele suportate de PC LANs, pana la cele utilizate de marile sisteme de computere mainframe.
Un sistem Oracle distribuit poate fi un amestec de baza de date distribuita si sisteme de procesare distribuite.
Procesarea distribuita si baza de date distribuita nu sunt acelasi lucru, desi au similaritati. Intr-un sistem de procesare distribuita, procesarea datelor (cautarea informatiei, stocarea rezultatelor) este distribuita. Intr-o baza de date distribuita, datele sunt distribuite in baza de date pe mai mult de o masina.
Un sistem de baze de date distribuit ii apare utilizatorului ca fiind un server unic dar este de fapt un set de doua sau mai multe servere. Datele pe fiecare server pot fi accesate simultan si modificate printr-o retea. Fiecare server intr-un sistem distribuit este controlat de administratorul local al bazei de date (DBA), si fiecare server coopereaza pentru mentinerea consistentei bazei de date globale.
Observati in figura 6-1 ca statiile de lucru sunt clienti si se conecteaza la serverul de baza de date prin reteaua de comunicatie. Cele doua servere, HQ si SALES comunica de asemenea prin retea pentru a mentine consistenta datelor, deoarece modificarile asupra bazei de date SALES pot avea impact asupra bazei de date HQ ca atunci cand a fost implementata replicarea datelor.
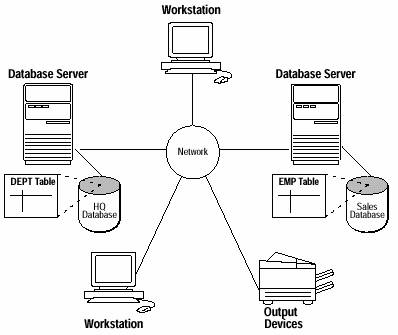
Figure 6-1 Un Environment Distribuit.
Figura 6-2 ilustreaza cum lucreaza impreuna serverele de baze de date HQ si SALES.
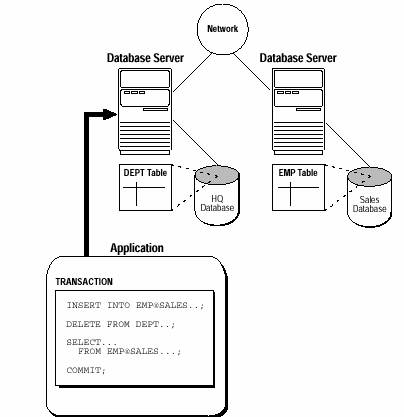
Figure 6-2 Un exemplu de Arhitectura Cooperativa de Server
De notat ca propozitia INSERT include locatia bazei de date de accesat (SALES) deoarece clientul de la care a pornit propozitia SQL e conectat direct numai la serverul de baza de date HQ.
Un nod intr-un sistem distribuit poate fi un client, un server sau amandoua. Fiecare computer din sistem este un nod.
Capacitatea de a asigura replicarea in siguranta a datelor Teste un factor extrem de important (si complex) intr-un sistem distribuit. Replicarea datelor inseamna ca orice obiect dat poate avea mai multi reprezentanti storati pe diferite site-uri si ca daca fiecare reprezentant este potential actualizabil, trebuie sa existe un mecanism pentru a asigura de catre toti reprezentantii reflectarea modificarilor efectuate.
Un client se poate conecta direct sau indirect la un server. In Figure 6-2, cand aplicatia client emite prima si a treia propozitie, clientul este conectat direct la baza de date intermediara HQ si indirect la baza de date SALES ce contine datele la distanta (remote).
Autonomia site-ului inseamna ca fiecare server care participa intr-un sistem distribuit este administrat independent (pentru operatiunile de securitate si salvare) de pe alte servere.
O interogare la distanta (remote) este o interogare care selecteaza informatia din una sau mai multe tabele remote, toate fiin la acelasi nod remote.
O actualizare remote este o actualizare ce modifica datele in una sau mai multe tabele, toate fiind localizate la acelasi nod remote.
O interogare distribuita regaseste informatia din doua sau mai multe noduri.
O actualizare distribuita modifica datele pe doua sau mai multe noduri. O actualizare distribuita este posibila utilizand o procedura sau un triger, care include doua sau mai multe actualizari remotecare acceseaza datele pe noduri diferite. Propozitiile din program sunt trimise la nodurile remote, iar executia programului reuseste sau esueaza unitar.
O tranzactie remote este o tranzactie care contine una sau mai multe propozitii remote, toate referind acelasi nod remote. O tranzactie distribuita este orice tranzactie care include una sau mai multe propozitii, individual sau ca grup, actualizeaza sau interogheaza datepe doua sau mai multe noduri distincte ale unui sistem distribuit. Daca toate propozitiile unei tranzactii refera numai un singur nod remote, tranzactia este remote (la distanta), si nu este distribuita.
Un sistem eficient, distribuit sau ne-distributed, trebuie sa garanteze ca toate declaratiile dintr-o tranzactie sunt fie confirmate fie derulate inapoi ca un intreg, astfel incat datele din baza de date logica sa poate fi pastrate in mod consistent.
Gestionarea restaurarii tranzactiilor garanteaza ca toate servere de baze de date dintr-o tranzactie distribuita fie sunt confirmate fie se deruleaza inapoi declaratiile tranzactiei. Gestionarea restaurarii tranzactiei protejeaza de asemenea implicit operatiunile DML efectuate de constrangerile de integritate, aprelarile de proceduri la distanta, si triggeri.
Functionalitatea unui sistem distribuit trebuie asigurata de asa maniera incat complexitatea sistemului sa fie transparenta atat pentru utilizator cat si pentru administratori.
O arhitectura distribuita ar trebuie sa asigure si facilitati de replicare transparenta a datelor printre nodurile sistemului.