|
|
|
|
Procesorul este o resursa importanta in cadrul unui sistem de calcul. In general, in sistemele multiproces, nu exista posibilitatea de a avea un singur proces pentru fiecare procesor a.i sa se obtina un paralelism evident.
Exista 2 posibilitati:
lasam procesele sa ruleze pe rand;
impartim timpul de rularea procesorului intre procesele existente la un moment in sistem (in aceste caz putandu-se vorbi de un pseudo-paralelism);
Revine in sarcina sistemului de operare decizia de a alege procesul care va fi rulat in continuare.
Planificarea se poate face pe 2 niveluri:
nivelul cel mai coborat, prin planificarea pe termen scurt a proceselor;
nivelul de comunicare, prin planificarea pe termen mediu a job-urilor (job-ul poate avea mai multe procese); fiecare job dispune de o masina virtuala, cu resurse virtuale;
Conceptul de baza al planificarii procesorului este acela de proces.
Un proces este un program de executie definit prin imaginea procesului. Aceasta imagine este formata din:
1) segmentul de cod
2) segmentul de date
3) stiva
4) contorul de program
5) continutul registrilor
6) toate informatiile care fac ca un proces sa poate fi rulat.
Pentru a gestiona procesele existente in system, planificatorul trebuie sa cunoasca starea procesului (procesele din sistem, imaginea lor la un moment dat). Pentru a realiza aceste lucruri, planificatorul foloseste anumite structuri de date.
Conceptual, fiecare proces are propriul sau procesor virtual.
De fapt, procesorul real comuta de la un proces la altul, dar pentru a intelege acest lucru e mai usor sa consideram o colectie de procese ruland in mod pseudo-paralel. Aceasta comutare se numeste multiprogramare.
 In fig a) se poate vizualiza
multiprogramarea pentru patru programe aflate in memorie, utilizand un singur contor de program. Un contor de program:a)
In fig a) se poate vizualiza
multiprogramarea pentru patru programe aflate in memorie, utilizand un singur contor de program. Un contor de program:a) 
a) b)
 c)
c)
A
In fig b) se observa cum este abstractizata multiprogramarea in patru procese, fiecare cu propriul sau flux de control (adica cu propriul contor de program), fiecare ruland independent fata de celelalte.
In figura c) se observa vizualizarea in timp a executiei proceselor, dar la orice moment de timp este rulat un singur proces.
Pentru a intelege plenificarea pe termen scurt, se considera urmatorul exemplu:
|
SO |
|
|
|
|
|
|
|
P4 |
|
|
![]()
![]()
![]()
Se considera ca in sistem exista 4 programe utilizator care utilizeaza o banda magnetica (dispozitiv I/O). Fiecare din cele 4 procese din sistem e lasat de ruleze o cuanta de timp sau se blocheza.
Procesul P1 este in rulare, iar procesele P2, P3, P4 sunt pregatite asteptand eliberarea procesorului. Cand P1 executa o operatie de I/O el se va bloca pentru ca aceasta dureaza foarte mult. Controlul va fi dat altui proces (P3). P3 va rula o vreme si va lansa o cerere de I/O. P3 se va bloca si un alt proces va primi controlul (de ex P2) care nu face cerere I/O si isi foloseste intreaga cuanta de timp, dupa care va fi rulat P4.
Pentru a se putea realiza aceasta comutare intre procese, sistemul de operare trebuie sa foloseasca anumite structuri de date, numite "blocuri de control ale proceselor" (PCB). Aceste structuri contin informatii despre starea proceselor, contorul programului, stiva, alocarea memoriei, starea fisierelor deschise, informatia pentru planificare si orice alta informatie despre proces care trebuie sa fie salvata cand procesul comuta din starile "in rulare" in "gata pentru executie", pentru ca apoi sa poate fi restartat mai tarziu ca si cand nu ar fi fost stopat. Campurile exacte continute pot varia de la sistem la sistem referindu-se la managementul proceselor, al memoriei sau sitemului de fisiere. In general, structura unui PCB este urmatoarea:
|
Identificator Proces |
|
Stare curenta |
|
Prioritatea |
|
Zona salvata pe stiva |
|
Lista procese |
|
Alte |
Figura urmatoare prezinta cateva din cele mai comune campuri prezente in sistemele UNIX:
|
Managementul proceselor |
Managementul memoriei |
Managementul fisierelor |
|
Registrii |
Pointer la segmentul .text |
Masca Umask |
|
Contor program |
Pointer la segmentul .data |
Directorul radacina |
|
Cuvant de stare al programului |
Pointer la segmentul .bss |
Directorul de lucru |
|
Pointer stiva |
Starea de iesire |
Descriptori fisier |
|
Starea procesului |
Starea semnalelor |
UID-ul efectiv |
|
Momentul cand a pornit procesul |
ID-ul procesului |
GID-ul efectiv |
|
Timpul de utilizare proces |
Procesul parinte |
Parametrii apel sistem |
|
Pointer la coada de mesage |
Grupul procesului |
Diferite flag-uri |
|
Identificator proces |
UID-ul real |
|
|
Diferite flg-uri |
UID-ul efectiv |
|
|
|
GID-ul real |
|
|
|
GID-ul efectiv |
|
|
|
Masca ptr semnale |
|
|
|
Diferite flag-uri |
|
Un proces aflat in rulare care face o cerere de acaparare a unei resurse (procesor, dispozitiv I/O) este pus intr-o lista de asteptare a proceselor. Daca un proces asteapta la mai multe resurse, atunci acelasi proces (structura PCB) va putea sa apara in mai multe liste. In acest caz se ridica o problema: daca fiecare resursa are o lista proprie de procese, este dificil pentru planificator sa scaneze toate aceste liste pentru a decide daca un proces poate sa ruleze sau nu. Atunci se foloseste varianta existentei unei singure liste de procese care e subdivizata in subliste corespunzatoare proceselor care asteapta la aceeasi resursa. O astfel de lista este si "tabela de procese" care exista in UNIX si in alte sisteme de operare. Datorita faptului ca memoria folosita de sistemul de operare este limitata, nr. de procese este maxim.
Planificarea procesului e facuta in concordanta cu mai multe evenimente care pot aparea. Astfel de evenimente pot fi:
o procesul s-a terminat
o procesul se blocheaza datorita unei cereri de I/O
o solicitarea unei resurse
o aparitia unui proces prioritar in sistem care solicita procesorul
o expirarea unei cunate de timp
o aparitia unei erori
Indiferent care este evenimentul aparut, pentru a realiza comutarea de procese, planificatorul trebuie sa scaneze intr-o lista de PCB-uri pentru a alege un proces. Acest lucru poate fi facut pe baza unor algoritmi de planificare care vizeaza buna functionare a sistemului. Obiectivul este ca schimbul intre procese sa se faca foarte repede pntru a nu bloca procesorul. Exista 2 alternative de a gestiona liste de procese pregatite pentru executie:
1) inserarea proceselor in lista ordonat in functie de prioritatea proceselor. Dezavantaj: inserarea intr-o lista ordonata e costisitoare. Avantaj: intotdeauna va fi planificat procesul aflat la capul listei.
2) Inserarea proceselor la inceputul listei indiferent de proprietate cand se face o comutare intre procese, trebuie parcursa lista pentru a decide care dintre procese va fi planificat. Avantaj: inserarea este foarte rapida. Dezavantaj: cautareaeste costisitoare.
Obiectivele urmarite de algoritmii pt planificarea proceselor sunt complexe, dar si contradictorii:
a) Sa se asigure ocuparea procesorului 100% din timp
b) Minimizarea timpilor de asteptare pt utilizator care creeaza procese interactiv;
c) Minimizarea timpilor de asteptare pt utilizatorii care au lansat procese in background (s-ar putea sa fie amanate pe timp nedefinit)
d) Primirea de catre fiecare proces a unei cunate de timp fixe
In realizarea planificarii proceselor trebuie avut in vedere comportamentul nepredictiv al proceselor din sistem (unele procese fac mai multe calcule, fara operatii de I/O, altele invers, se blocheaza repede).
Dupa expirarea unei cuante de timp (masurate prin intreruperi de la ceasul sistem), planificatorul va decide daca un proces isi va continua executia sau nu. Se pot utiliza 2 strategii:
a) de a intrerupe un proces in mod fortat cand sistemul de operare decide acest lucru si de a da voie altui proces sa fie rulat, cu prelevare fortata;
b) procesele sa ruleze pana se termina, strategie fara prelevare fortata. In acest caz, unele procese pot fi intrerupte intr-un mod nedefinit daca un proces planificat inainte va rula foarte mult. Deci aceasta strategie nu se utilizeaza in sistemul de uz general ci in sistemele dedicate in care exista un proces master care ae controlul proceselor fiu (in acest caz procesul parinte stie comportamentul proceselor fiu si la aparitia unei erori, el poate omora (criminalu'☺) procesul care a generat eroarea)
Principalii algoritmi folositi in planificarea proceselor sunt:
1. Round Robin:
Cel mai simplu algoritm de planificare, in care un proces este lasat sa ruleze o cuanta de timp, Δt sau pana se blocheaza datorita accesului la o resursa.
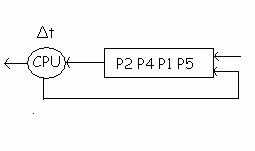
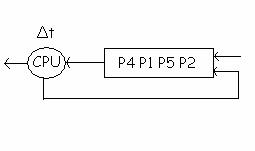
Sa consideram situatia in care procesul P2 este rulat de catre procesor, lista proceselor aflate in asteptare sunt P4, P1, P5. Procesul P2 este lasat cu o cuanta de timp Δt pentru rulare, dupa care e trecut la coada listei si controlul e dat urmatorului proces P4. Astfel se obtine marirea eficientei sistemului, planificarea se face foarte repede. Dezavantajul este acela ca nu exista un sistem de prioritati, astfel ca procesele care executa operatii de I/O sunt defavorizate. Trebuie avuta in vedere si alegerea cuantei de timp Δt (daca este prea mic, nu este eficent datorita faptului ca exista multe comutari intre procese si ca presupune implementarea prea multor structuri de date; daca este prea mare, raspunsul la procese intractive poate fi nul).
2. Round Robin limitat:
In acest caz procesele sunt rulate in sistem folosind politica Round Robin de un numar specificat de ori, dupa care, daca procesul nu s-a terminat, el este trecut in alta coada si va fi executat numai daca nu exista si alte procese in sistem. In acest mod se favorizeaza procesele scurte.
3. Round Robin cu mai multe nivele si feed-back:
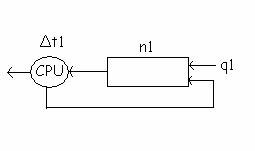
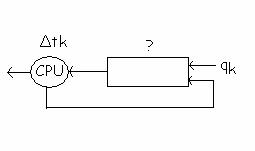
Δt1 < Δt2 < Δtk
In acest caz, un proces nou venit este pus in coada q1 si e lasat sa ruleze de n1 ori, avand alocata o cuanta Δt1, apoi, daca nu s-a terminat, el este trecut in q2, unde va fi rulat de n2 ori, cu o cuanta de timp Δt2. Daca nu s-a terminat coboara pana ajunge la ultima coada qk, unde e lasat sa ruleze un numar specificat de ori.
Planificarea unui proces in qj se face numai daca nu exista nici un proces in cozile q1qj-1. Alegerea timpilor de rulare Δt1 < Δt2 < Δtk incearca sa faca, ca timpii de rulare sa fie cat de cat corecti, pentru ca un proces aflat mai in jos va fi planificat mai rar. Feed-back-ul se refera la faptul ca, dupa o perioada de timp specificata, daca nici un proces din qj nu e palnificat pentru executie, atunci primul proces din aceasta coada va fi trecut la sfarsitul cozii qj-1, deci fiecare proces poate ajunge la nivelele sueperioare.
4. Planificarea invers proportionala cu cuanta de timp ramasa
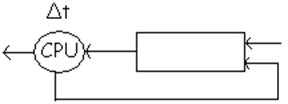
Cand un proces intra in sistem, este pus in coada, apoi, dupa ce este
planificat pentru executie pentru prima data, se pot intalni mai multe
situatii:
a) daca s-a folosit toata
cuanta de timp Δt, acesta se blocheaza si este pus in coada k, la sfarsit
b) daca s-a folosit ½ Δt si apoi s-a facut o operatie de I/O si s-a blocat, procesul va fi pus la jumatatea cozii
c) daca imediat cand a obtinut procesorul s-a blocat (ce fraier☺), procesul va fi pus la inceputul cozii
Aceasta politica de planificare favorizeaza procesele care fac operatii de I/O (care sunt lungi) deoarece este bine ca atunci cand un proces a terminat o operatie de I/O sa primeasca procesorul cat mai repede; atunci procesul va fi pus la inceputul cozii imediat ce termina operatia de I/O.
5. Planificarea cu prioritati:
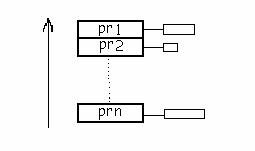
In acest caz fiecare proces are asociata o prioritate, fiecarui nivel de prioritate, fiindu-i asociata o coada de procese. Prioritatea maxima pe care o poate avea un proces este 1. Odata cu trecerea timpului prioritatea unui proces scade. Cand prioritatea procesului aflat in rulare scade si devine mai mica decat prioritatea altor procese gata pentru executie, procesul va fi intrerupt si va fi pus in coada asociata nivelului sau de prioritate. Prioritatea procesului poate creste daca la un moment dat in memorie exista procese pregatite, dar nici unul cu prioritate mai mare nu ruleaza. Prioritatea pe care o are procesul initial poate fi dobandita in doua moduri:
a) static - data in momentul cererii procesului in functie de tipul de operatii
executate de proces (sau clasei de procese din care face parte);
b)dinamic - cea pe care o are procesul la un moment dat conform algoritmului
descris de cresterea/scaderea prioritatii (procesele care executa operatii de I/O au prioritate mare deoarece executa operatii lungi, stau blocate mult timp)
6. Tratamentul preferential al proceselor interactive:
Se bazeaza pe ideea ca utilizatorul nu trebuie sa astepte cand interactioneaza cu procesele, deci procesele care fac operatii de I/O vor avea prioritate mare, in defavoarea proceselor care executa in special calcule.
7. Planificarea bazata pe criterii de performanta asociate proceselor:
Daca un proces dureaza prea mult, prioritatea lui scade - in acest caz sistemul favorizeaza procesele scurte. Echilibrarea operatiilor si imbunatatirea functionarii globale a sistemului (se vor pune in aceeasi coada de prioritate atat procesele care folosesc intensiv procesorul cat si cele care executa operatii de I/O).
Un aspect important il constituie separarea dintre ceea ce inseamna mecanismul de planificare si politica de planificare. Pana acum am considerat ca procesele apartin utilizatorilor diferiti si se vor afla in competitie pentru acapararea procesorului. Se poate intampla ca un proces sa aiba mai multe procese fiu care sa ruleze sub controlul sau. Este posibil ca procesul parinte sa cunoasca foarte bine comportamentul fiilor sai.
Din pacate, posibilitatile de planificare de pana acum nu accepta anumiti paarmetrii de la procesele utilizator in legatura cu decizia de planificare.
Solutia este separarea intre mecanismul de planificare si politica de planificare (ceea ce inseamna ca algoritmul de planificare este parametrizat, dar parametrii pot fi stabiliti de catre procese).
Pana cum am considerat ca toate procesele se afla in memorie, ceea ce nu este adevarat. Daca nu este disponibila suficienta memorie, unele dintre procese vor fi trimise pe disk. Acest lucru influenteaza major planificarea, cand procesul planificat se afla pe disk in loc sa fie in memorie (timpii de aducere sunt mari). In acest caz planificarea se face pe doua nivele:
a) de baza : planificarea proceselor aflate deja in memorie
b) cel care decide ca procese din memorie vor fi duse pe disk si care vor fi procesele aduse de pe disk in memorie
In cazul b) se vor avea in vedere urmatoarele criterii:
prioritatea procesului (daca e maxima, procesul nu e dus pe disk)
dimensiunea memoriei ocupate de proces (un proces mare necesita timp mare de ducere sau de aducere de pe disk)
timpul de cand procesul se afla in memorie sau pe disk
cat timp al procesorului a folosit procesul respectiv