|
|
|
|
Organizarea datelor - access
Data este un model de reprezentare a informatiei, accesibil unui anumit procesor (om, program calculator). Cu acest model se opereaza pentru a obtine noi informatii despre fenomenele si procesele lumii reale.
Colectia de date este o multime relativ omogena de date care priveste un anumit domeniu, proces, activitate sau obiect si organizata si dispusa sistematizat pe un suport de memorie. Daca este definit un mecanism de selectare a elementelor colectia de date se numeste structura de date.
Organizarea datelor reprezinta procesul de identificare, definire, evaluare, structurare si memorare a informatiilor, in cadrul unui sistem informational, in general sau in activitatea de elaborare a unui program, in particular. Organizarea datelor presupune:
definirea, structurarea, ordonarea si gruparea datelor in colectii de date omogene;
stabilirea relatiilor dintre date, dintre elementele colectiilor si dintre colectii;
stocarea datelor pe suport informational, prelucrabil prin intermediul unui sistem de calcul.
Scopul organizarii datelor il reprezinta regasirea automata a datelor dupa diverse criterii.
Obiectivele urmarite in organizarea datelor:
minimizarea timpului de acces la date;
minimizarea spatiului de memorie (interna si externa) ocupat de date;
minimizarea redundantei datelor;
reflectarea tuturor legaturilor dintre obiectele, fenomenele si procesele economice pe care aceste date le reprezinta;
sa permita schimbarea structurii datelor si a relatiilor dintre acestea fara modificarea programelor care le prelucreaza.
1.1 Clasificarea datelor
Clasificarea datelor se realizeaza pe baza mai multor criterii. Datele din sistemul informational, generate in timpul si datorita proceselor economice, se impart in functie de nivelul de detaliere in doua categorii: date elementare si date compuse.
Datele elementare, numite si scalari, sunt indivizibile, atat la nivel informational cat si la nivel de prelucrare. De exemplu cursul BNR al unei valute la o anumita data sau pretul unui produs dintr-o factura. Datele elementare sunt identificate prin nume (identificator) si au o anumita valoare.
Identificatorul datei (numele) este un simbol asociat datei pentru a o distinge de alte date si pentru a o referi in procesele de prelucrare.
Atributele precizeaza proprietatile datei si determina modul in care va fi tratata in procesul de prelucrare:
tip intreg, real, logic, sir de caractere etc.
precizia reprezentarii interne: virgula mobila precizie simpla, virgula mobila precizie dubla etc.
modul de adresare a memoriei
valoarea initiala etc.
Valorile datei se pot preciza prin enumerare si sunt strans legate de tipul datei . Daca pe parcursul proceselor de prelucrare data pastreaza aceiasi valoare este denumita constanta. Pentru constante se utilizeaza ca identificator valoarea acestora. Daca valorile datei sunt diferite in timpul procesului de prelucrare atunci datele se numesc date variabile sau variabile.
Din punct de vedere fizic unei date ii corespunde o zona de memorie de a anumita marime identificata printr-un nume, situata la o anumita adresa.
Cele mai des intalnite tipuri de date elementare sunt:
numerice - sunt incluse numerele intregi, reale si complexe (virgula fixa, virgula mobila, precizie simpla, precizie dubla etc.). Asupra lor se pot realiza operatii de adunare, scadere, inmultire, impartire etc.;
logice (boolean) - utilizate pentru precizarea starilor de adevar (adevarat, fals). Asupra acestora se pot efectua operatii logice precum AND, OR, NOT, XOR;
caracter (text, string) - contin o multime de simboluri alfanumerice utilizand codul ASCII. Asupra acestora se pot defini operatii de cautare, concatenare, ordonare.
In afara de aceste tipuri de date mai exista si tipuri dependente de limbajul de programare (de exemplu Date, DateTime, Currency)
Datele compuse sunt multimi de date elementare, omogene din punct de vedere al descrierii si al prelucrarii. Datele compuse au aparut din nevoia de a descrie din punct de vedere informational un anumit obiect sau proces din realitatea inconjuratoare ale carui caracteristici nu puteau fi sintetizate de un singur scalar.
Datele pot fi clasificate in functie de modul de alocare a memoriei, astfel existand date de tip static si date de tip dinamic. La datele de tip static, memoria este alocata la incarcarea programului, pe cand la datele de tip dinamic memoria este alocata in momentul executiei programului.
Majoritatea aplicatiilor economice opereaza cu cele doua categorii de structuri existente: structuri interne si structuri externe.
Structurile de date interne se refera la modul de amplasare in memoria interna a datelor elementare apartinand unei colectii. In aceasta categorie sunt incluse structurile de tip masiv, inregistrare (articol), multime, lista si arbore.
Structurile externe se refera la modul de memorare a datelor pe suporti de memorie magnetica. Din aceasta categorie fac parte fisierele si bazele de date.
1.2 Colectii de date
Colectiile de date definesc multimi relativ omogene de date care descriu un domeniu, un proces, o activitate sau un obiect al lumii reale.
Definirea in plan informational a colectiilor de date presupune intelegerea conceptelor de entitate, membru, atribut, valoare.
Entitatea reprezinta o componenta unitara care poate fi individualizata informational intr-un domeniu, o activitate sau intr-un mediu economic. De exemplu, in mediul sanitar exista entitatea "medici" si entitatea "pacienti". In activitatea de export a unei firme sunt entitatile "contracte", "produse", "clienti", si "facturi". In activitatea desfasurata in procesul de invatamant avem entitatile "profesori" si "studenti".Entitatea este conceptul corespondent, in plan informatic, al unei colectii de date.
Atributele reprezinta caracteristicile care descriu informational proprietatile unei entitati. Asa cum un corp, de exemplu, are drept caracteristici fizice: greutatea, inaltimea, latimea, volumul, densitatea etc., tot asa o entitate are propriile sale atribute informationale. Un contract de export este descris de urmatoarele atribute: numar, data, codul si denumirea produsului, cantitate, pret, valoare, denumirea clientului extern si tara, termen de livrare etc.
Membrii unei entitati reprezinta elementele colectiei de date. Ei mostenesc individual atributele care descriu entitatea, de aceea se considera ca o entitate este o colectie omogena de date. Toti membrii unei entitatii au acelasi set de atribute, doar atributele au valori proprii fiecarui membru.
Fiecare entitate este identificata printr-un nume. De asemenea si fiecare atribut al entitatii poarta un nume distinct. Atributele fiind numite, adesea, campuri, atunci si numele atributelor apar ca nume de campuri.
O entitate este complet definita daca i se precizeaza numele (identificator). Atributele sunt definite daca li se precizeaza numele, tipul si lungimea. Precizarea acestor elemente se numeste descriere logica a entitatii
In procesul prelucrarii, datele din diversele colectii sunt supuse unor corelatii, inlantuiri, asocieri. Aceste legaturi servesc pentru completarea datelor dintr-o colectie cu date preluate din alte colectii, sau pentru separarea si prelucrarea distincta a unor grupe de date. Legaturile se realizeaza, practic, prin folosirea unor atribute comune entitatilor intre care dorim sa existe anumite relatii.
Pentru exemplificare se vor considera entitatile FURNIZORI si CONTRACTE. Daca la un moment dat se doreste gruparea tuturor contractelor incheiate cu un anumit furnizor, se constata ca este necesar un camp comun (existent in cele doua entitati), prin intermediul caruia sa se realizeze extragerea si gruparea informatiilor dorite, din cele doua colectii (figura 1.2.1.).
Entitatea FURNIZORI
Atribut
Tip
Lungime
CodFurnizor
N
3
DenumireF
C
20
Adresa
C
30
Entitatea CONTRACTE
Atribut
Tip
Lung
Nr Contract
N
4
Data Contr
D
8
CodFurnizor
N
3
Valoare
N
10

Membri entitatea FURNIZORI
CodFurnizor
DenumireF
Adresa
1
F1
Pitesti
2
F2
Bucuresti
3
F3
Pitesti
4
F4
Craiova
Membri entitatea CONTRACTE
Nr Contract
Data Contr
CodFurnizor
Valoare
100
10.01.2008
1
1500
101
05.02.2008
2
1000
102
14.02.2008
3
800
103
12.03.2008
1
1200
104
23.03.2008
4
1600
105
03.04.2008
3
600
106
27.04.2008
2
1100

FURNIZOR F1:
Nr Contract
Data Contr
CodFurnizor
DenumireF
Adresa
Valoare
100
10.01.2008
1
F1
Pitesti
1500
103
12.03.2008
1
F1
Pitesti
1200
Figura 1.2.1. Corelarea datelor pe baza relatiilor dintre entitati
Complexitatea problemelor economice se reflecta si in diversitatea si complexitatea relatiilor dintre colectiile de date. Intre colectiile de date exista corelatii, legaturi care trebuie sa se regaseasca si intre entitati.
Aceste legaturi permit asocierea datelor, gruparea a doua sau mai multor entitati sau selectarea unui anumit subset de membri in vederea prelucrarii lor distincte. Legaturile se pot realiza prin diverse modalitati, cel mai frecvent fiind utilizata varianta de plasare de atribute comune in cadrul entitatilor asociate.
1.3 Modelare
Prin modelare se intelege reprezentarea unui obiect, fenomen, sau proces din lumea reala intr-un anumit sistem(matematic, fizic, informatic). Modelul este creat pentru a permite studiul obiectului sau fenomenului din lumea reala, intr-un anumit context.
Un model va pastra numai acele caracteristici care sunt importante pentru reprezentarea acestuia in contextul in care va functiona. De exemplu, daca dorim sa cream modelul unui calculator in scopul studierii performantelor sale, atunci modelul realizat va contine informatii referitoare la viteza procesorului, la memorie, dar nu va contine informatii referitoare la materialul sau culoarea din care este confectionata carcasa, deoarece acestea nu au nici un rol in contextul respectiv.
Un obiect reprezinta o entitate (ceva bine definit) care are o anumita structura, anumite caracteristici si o anumita functie.
Un obiect se caracterizeaza prin:
- Proprietati, care reprezinta structura si atributele unui obiect.
- Metode, care reprezinta actiunea (actiunile) pe care poate sa le efectueze un obiect.
Un model realizat in sistemul informatic contine date sau informatii si prelucrari care provin din proprietatile si metodele obiectului sau fenomenului supus modelarii. Vom avea astfel doua procese de modelare si anume: modelarea datelor si modelarea prelucrarilor. Aceste procese vor parcurge mai multe grade de abstractizare, obtinandu-se astfel trei tipuri de modele: conceptual, logic si tehnic. Modelul care poate fi implementat pe calculator este modelul tehnic.
In figura 1.3.1 este prezentata activitatea de modelare efectuata asupra unui obiect sau fenomen din lumea reala in scopul realizarii unei aplicatii informatice.
![]()
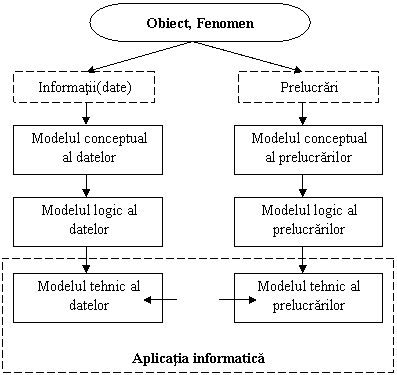 Figura 1.3.1 Activitatea de modelare
Figura 1.3.1 Activitatea de modelare
1.3.1 Modelarea conceptuala
Un model conceptual este un ansamblu de concepte si reguli de combinare a acestor concepte permitand reprezentarea realitatii circumscrise domeniului supus informatizarii.
Modelele conceptuale utilizeaza abstractii reprezentand lumea reala ca pe o colectie de entitati si de legaturi, stabilite intre acestea. Majoritatea modelelor permit definirea de restrictii descriind aspectele
statice, dinamice sau chiar temporale ale entitatilor.
Un exemplu de model conceptual al datelor este modelul Entitate -Asociere(EA). Modelul EA urmareste obtinerea unei reprezentari fidele, utilizand concepte specifice, a realitatii (problemei de rezolvat ce urmeaza a fi informatizata). Aceasta reprezentare a lumii reale se va realiza facandu-se abstractie de orice restrictie fie ea informatica sau organizatorica. Pornind de la semantica obiectelor lumii reale si a legaturilor stabilite intre acestea, modelul EA serveste in egala masura ca un mijloc de comunicare intre modelator (informatician) si viitorul utilizator al sistemului (beneficiarul sistemului informatic), care descrie realitatea supusa modelarii in conformitate cu propria lui perceptie.
Conceptele de baza ale modelului Entitate Asociere sunt:
ENTITATEA care reprezinta un obiect al realitatii modelate caracterizat printr-o existenta proprie, cu o identitate proprie (care-l face identificabil in raport cu celelalte obiecte de acelasi tip) si o multime de caracteristici care exprima proprietatile acestuia. In activitatea de modelare interesul se focalizeaza pe definirea tipurilor de entitati apartinand problemei de rezolvat si nu pe entitati care reprezinta realizarile tipurilor de entitati. Tipul de entitate reprezinta un concept generic desemnand multimea tuturor entitatilor prezentand aceleasi caracteristici constructive. De exemplu, tipul de entitate STUDENT desemneaza ansamblul studentilor caracterizati prin aceleasi trasaturi comune: numar matricol, nume, data-nasterii, localitatea, facultatea, specializarea etc.
ATRIBUTUL defineste o proprietate distincta a unei entitati. Fiecare atribut prezinta un domeniu, adica o multime de valori admise. Intr-o entitate se regasesc realizari corespunzatoare caracteristicilor definitorii pentru tipul de entitate.
ASOCIEREA dintre entitati exprima legatura stabilita dintre acestea si rolul pe care il joaca fiecare entitate participanta la legatura. Exprimand o legatura dintre entitati ea nu are o existenta de sine statatoare. O asociere poate prezenta unul sau mai multe atribute proprii cu rol de a caracteriza, explicita, legatura stabilita intre entitatile participante la asociere. Tipul de asociere se defineste ca ansamblul legaturilor, prezentand aceiasi semnificatie, dintre entitatile apartinand la doua sau mai multe tipuri de entitati.
Pentru exemplul din figura 1.2.1 se poate construi modelul EA astfel:
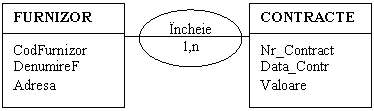 Figura 1.3.1.1 Modelul EA
Figura 1.3.1.1 Modelul EA
Intre realizarile a doua tipuri de entitati se pot stabili mai multe asocieri prezentand semantica diferita.
Exemplu: un profesor lucreaza la o disciplina cu un grup de studenti, unora dintre acestia (maxim 10) conducandu-le si proiectul de semestru la disciplina respectiva(figura 1.3.1.1)

Figura 1.3.1.2 Modelul Entitate Asociere
Modelul EA este completat de restrictiile de integritate ce definesc cerintele pe care datele trebuie sa le respecte pentru a fi corecte si coerente in raport cu realitatea pe care o reflecta. Restrictiile de integritate privesc:
valorile pe care le pot lua atributele entitatilor si asocierilor;
valorile identificatorilor entitatilor;
rolurile jucate de entitati in asocierile la care participa;
asocierile stabilite intre entitati.
1.3.2 Modelarea logica
Modelarea logica reprezinta aducerea modelului conceptual intr-o forma in care prin precizarea anumitor metode de organizare si prelucrare a datelor, sunt stabilite anumite cerinte informatice pe care modelul trebuie sa le indeplineasca.
Astfel, pentru crearea modelului logic al datelor, trebuie tinut cont de modul de organizare pe care il vor avea acestea pe calculator, si anume (asa cum se va arata in continuare) in fisiere clasice sau in baze de date. De asemenea daca se doreste un model logic bazat pe baze de date, va exista posibilitatea alegerii intre mai multe tipuri de arhitecturi (ierarhic, retea, functional, deductiv, orientat obiect, etc.).
De asemenea, pentru crearea modelului logic al prelucrarilor, trebuie tinut cont in general de principiile sistemului de programare ce se va utiliza: procedural, formal, LMD (limbaj de manipulare a datelor) etc.
Modelul logic relational, creeaza suportul necesar pentru definirea bazelor de date relationale (ca Microsoft Access). Elementele de baza definite in acesta sunt relatiile (ce provin din entitatile si asocierile modelului conceptual).
1.3.3 Modelarea tehnica
Modelul tehnic, reprezinta aducerea modelului logic intr-o forma precisa, dependenta strict de hardware-ul (calculatoarele, reteaua de calculatoare, echipamentele de transmisie a datelor, etc.) si de software-ul (sistemul de operare, limbajele de programare, SGBD-ul (Sistemul de gestiune al bazelor de date), alte programe utilitare, etc.) ce vor fi efectiv utilizate, prin modificarea componentelor definite la nivel logic functie de facilitatile oferite de echipamentele si produsule informatice folosite.
1.4 Metode de organizare a datelor
Exista doua metode de organizare a datelor:
in fisiere clasice;
in baze de date.
1.4.1 Organizarea datelor in fisiere
Principala forma de organizare externa a datelor este fisierul. Fisierul reprezinta o colectie organizata de date, omogena din punct de vedere al continutului si al prelucrarii, stocata pe un suport de memorie externa.
Fisierul ocupa un anumit spatiu pe suportul de memorie externa, spatiul alocat putand fi sau nu continuu, fiind sarcina sistemului de operare sa gestioneze alocarea fizica a acestuia pe suportul de memorie.
Datele intr-un fisier sunt structurate in inregistrari care au in general aceiasi structura.
Instructiunile specifice care manipuleaza un fisier de date trebuie sa rezolve in general urmatoarele categorii de probleme:
Descrierea structurii fisierului.
Conectarea si deconectarea programului la fisierul de date. Pentru aceste actiuni se folosesc termenii de deschidere si inchidere a fisierului.
Pozitionarea pe o anumita inregistrare, pentru a permite prelucrarea ei.
Citirea sau actualizarea(modificarea datelor dintr-un camp, adaugarea unor noi inregistrari sau stergerea unor inregistrari) inregistrarilor fisierului.
Exista doua metode de organizare si de accesare a datelor din fisierele clasice:
Organizarea datelor in fisiere clasice este o metoda rigida care creeaza destule neajunsuri utilizatorilor sistemelor de programe bazate pe acest tip de fisiere cum ar fi:
Independenta datelor fata de programele de aplicatii.
Frecvent exista situatii in care mai multe aplicatii folosesc aceleasi date. Programarea clasica necesita pentru fiecare program in parte descrierea aceleasi structuri de date. O modificare in aceasta structura de date implica refacerea tuturor programelor care au acces la aceasta.
Desi exista posibilitati de modernizare a programarii clasice prin proceduri, functii si fisiere incluse, totusi dependenta programului de structurile de date este foarte stransa in cazul lucrului cu fisiere clasice, ceea ce duce la greutati deosebite in activitatea de dezvoltare a aplicatiilor.
Redundanta datelor din fisierele clasice.
Notiunea de redundanta se refera la repetarea unor informatii. O aplicatie contine in general mai multe fisiere. Acestea au legaturi intre ele prin niste date comune. Aceste date comune (redundante) pot la aplicatii complexe sa ajunga in cantitati foarte mari. Acest lucru creeaza pe langa ocuparea unui spatiu de memorare inutil, in special dificultati in actualizarea fisierelor (deoarece modificarea unei date comune trebuie sa se faca in toate fisierele care o contin pe aceasta).
Integritatea datelor.
Notiunea de integritate se refera la faptul ca datele au o anumita structura si ele trebuie sa respecte anumite corelatii logice. De exemplu, daca avem un camp care reprezinta varsta unei persoane, o valoare negativa introdusa in acesta va determina o 'eroare logica' in date.
Integritatea datelor reprezinta poate cel mai important lucru pentru o aplicatie complexa. Fisierele clasice nu au metode speciale de verificare si protectie a structurilor logice care se creeaza intre datele apartinand unuia sau mai multor fisiere.
1.4.2 Organizarea datelor in baze de date
O baza de date (database) este o colectie de date corelate din punct de vedere logic, care reflecta un anumit aspect al lumii reale si este destinata unui anumit grup de utilizatori.
O baza de date poate fi folosita de una sau mai multe aplicatii, care vor gestiona o anumita activitate
Sistemele de baze de date sunt o componenta esentiala a vietii de zi cu zi in societatea moderna. In cursul unei zile, majoritatea persoanelor desfasoara activitati care implica interactiunea cu o baza de date: depunerea sau extragerea unor sume de bani din banca, rezervarea biletelor de tren sau avion, cautarea unei referinte intr-o biblioteca computerizata, cumpararea unor produse etc.
Bazele de date pot avea dimensiuni (numar de inregistrari) extrem de variate, de la cateva zeci de inregistrari (de exemplu, baza de date pentru o agenda cu numere de telefon) sau pot ajunge la zeci de milioane de inregistrari (de exemplu, baza de date de plata pentru plata taxelor si a impozitelor).
Utilizatorii unei baze de date au posibilitatea sa efectueze mai multe categorii de operatii asupra datelor memorate:
Introducerea de noi date (insert);
Stergerea unora din datele existente (delete);
Actualizarea datelor memorate (update);
Interogarea bazei de date (query) pentru a regasi anumite informatii, selectate dupa un criteriu ales.
In continuare sunt prezentate principalele obiective ale organizarii datelor in baze de date.
1. Asigurarea independentei relative a programelor fata de structura datelor este primul obiectiv al organizarii datelor in baze de date, si desigur cel mai important. El este indeplinit tocmai prin memorarea distincta a structurii logice a datelor in tabele.
2. Asigurarea unei redundante minime si controlate a datelor este al doilea obiectiv major al organizarii datelor in baze de date. Aceasta inseamna ca se urmareste pe cat posibil ca fiecare camp sa apara numai intr-un singur fisier, deci numai o singura data in baza. Exceptie fac campurile comune ce apar in fisiere distincte si campurile care fac necesara intregirea semnificatiei semantice a datelor, a intelesului acestora. Duplicarea datelor, redundanta, trebuie redusa la minim si mentinuta sub control.
O anumita redundanta trebuie acceptata pentru a asigura perfor-mante sporite programelor de accesare si prelucrare a bazei datelor. Redundanta minima se asigura prin tehnicile de proiectare a bazelor de date, de exemplu normalizarea bazelor de date relationale.
Celor doua obiective mentionate pana acum li se mai pot adauga si altele la fel de importante, cum ar fi:
Asigurarea unor facilitati sporite de utilizare se realizeaza prin punerea la dispozitia utilizatorilor a unei interfete prietenoase, ce permite un dialog concis pentru actualizarea si exploatarea bazei de date. Utilizatorii obisnuiti nu trebuie sa cunoasca structura intregii baze de date, ei pot sa utilizeze un limbaj mai apropiat de limbajul natural al procedurilor de actualizare, interogare si afisarea datelor din baza de date.
Securitatea datelor vizeaza prevenirea accesului neautorizat la baza de date, lucru posibil prin filtrarea drepturilor de acces ale fiecarui utilizator si printr-un sistem de parole multinivel.
Pastrarea integritatii datelor inseamna prevenirea distrugerii accidentale a fisierelor, fapt care obliga la instituirea unui set de proceduri de autorizare, dar si de confirmare a operatiilor de stergere, adaugare, precum si proceduri de realizare a unor copii de siguranta, a unor jurnale de urmarire a actualizarilor si proceduri de refacere a bazei de date, de restaurare a acesteia, in caz de incidente.
Partajabilitatea datelor trebuie inteleasa nu numai sub aspectul uti-lizarii in comun de catre mai multe aplicatii ale aceleiasi baze de date, ci ca posibilitate a dezvoltarii de noi aplicatii, de scriere de noi programe ce necesita poate chiar extinderea/modificarea aplicatiilor aflate deja in functiune.
1.5 Sisteme de gestiune a bazelor de date
Pentru crearea unei baza de date, pentru actualizarea permanenta a continutului acesteia si pentru consultarea si prelucrarea datelor stocate aici este utilizat un sistem specializat de programe cunoscut sub denumirea de sistem de gestiune a bazei de date (SGBD). El este un instrument software la care utilizatorul apeleaza pentru comunicarea cu baza de date la fel cum apeleaza la sistemul de operare Windows pentru a comunica cu computerul. El este plasat la un nivel intermediar intre utilizator si baza de date si asigura:
o interfata prietenoasa pentru comunicarea cu utilizatorul;
un mediu de programare performant, format dintr-un editor pro-priu de texte, un compilator, un utilitar pentru depanarea pro-gramelor, alte utilitare si instrumente de lucru cu baza de date.
Accesul la date se refera la operatiile de interogare si actualizare.
Interogarea este complexa si presupune vizualizarea, consultarea, editarea de situatii de iesire (rapoarte, liste, regasiri punctuale).
Actualizarea presupune 3 operatii: adaugare, modificare efectuate prin respectarea restrictiilor de integritate si stergere
Sistemul de gestiune a bazei de date dispune de un limbaj de descriere a datelor (DDL - Data Definition Language) si de un limbaj de manipulare a datelor (DML - Data Manipulation Language) cu ajutorul carora se asigura indeplinirea functiilor sale si anume:
definirea structurii bazei de date;
manipularea datelor, adica: incarcarea datelor in baza de date, actualizarea acestora, sortarea, indexarea, concatenarea s.a.;
utilizarea bazei de date, ceea ce inseamna: accesare rapida, listare, calcule, editarea rapoartelor etc.;
administrarea bazei de date, care presupune: optimizarea structurii bazei de date, validarea accesului la date, reorganizarea, compactarea bazei si refacerea bazei in caz de incidente pentru asigurarea securitatii sau integritatii bazei de date.
Un SGBD are rolul de a furniza suportul software complet pentru dezvoltarea de aplicatii informatice cu baze de date. El trebuie sa asigure:
minimizarea costului de prelucrare a datelor,
reducerea timpului de raspuns,
flexibilitatea aplicatiilor si
protectia datelor.
Din punct de vedere al modului de organizare, structurare si accesare a datelor, cele mai cunoscute sisteme de gestiune a bazelor de date sunt:
modelul ierarhic;
modelul de tip retea;
modelul relational.
1.5.1 Modelul ierarhic
Modelul de date ierarhic a fost primul model folosit pentru dezvoltarea bazelor de date. Cea mai cunoscuta realizare de SGBD ierarhic este sistemul IMS (Information Management System) dezvoltat de firma IBM in cadrul programului de cercetari Apollo, in perioada anilor 1960.
Bazele de date ierarhice se caracterizeaza prin faptul ca elementele componente au relatii de subordonare de tip unu la multi, astfel incat fiecare entitate are in subordine una sau mai multe entitati si este subordonata, la randul ei, unei singure entitati superioare. Modelul ierarhic se reprezinta prin urmatoarea diagrama de structura:
![]()
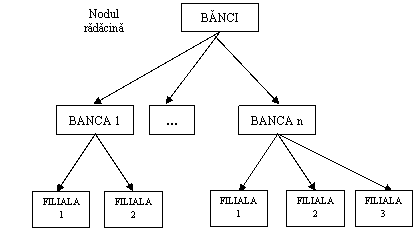 Figura 1.5.1.1.Diagrama de structura a
modelului ierarhic
Figura 1.5.1.1.Diagrama de structura a
modelului ierarhic
Intr-o asemenea ierarhie exista o inregistrare (nod) radacina si mai multe inregistrari (noduri) subordonate, cu legaturi de tip arbore, pe unul sau mai multe niveluri ierarhice.
Intre noduri se respecta urmatoare regula: fiecare nod intermediar, care nu este nici nod radacina si nici nod final, are un singur nod superior (parinte) si unul sau mai multe noduri inferioare (copii). Astfel, legatura dintre un nod parinte si unul fiu este de tip 1:N, in timp ce intre un nod copil si unul parinte este de tip 1:1.
O asemenea abordare rezolva problema redundantei. De asemenea, permite modificari relativ usoare a structurii bazei de date.
Modelul ierarhic creeaza totusi dificultati majore:
marimea exagerata a timpului de regasire a informatiilor(deci si a actualizarii datelor), deoarece pentru a ajunge la o anumita entitate este necesara parcurgerea fiecarei ramificatii de la varf pana la nivelul pe care se gaseste acesta;
numarul de ierarhii posibile creste combinatoric cu numarul inregistrarilor, ceea ce poate conduce la 'explozia' volumului de date, greu controlabil;
abordarea ierarhica nu este posibila pentru anumite structuri de date.
Aceste limite ale modelului ierarhic au determinat evolutia spre modelul retea.
1.5.2 Modelul retea
Modelul retea foloseste o structura de graf pentru definirea schemei conceptuale a bazei de date; nodurile grafului sunt tipuri de entitati (inregistrari - records), iar muchiile grafului reprezinta in mod explicit asocierile (legaturile-links) dintre tipurile de entitati.
Deosebirea fata de modelul ierarhic consta in aceea ca in modelul retea asocierile M:N se reprezinta fara duplicarea inregistrarilor, fiecare inregistrare putand fi referita de mai multe inregistrari, ceea ce elimina redundanta.
In modelul retea, un nod copil poate avea mai multe noduri parinti. Trebuie precizat faptul ca actualizarile la acest model inseamna adaugari, modificari si stergeri de realizari, atat asupra tipurilor de inregistrari cat si asupra legaturilor.
Modelul este destul de performant dar foarte complicat si dificil de implementat. Legaturile formeaza trasee care permit o regasire usoara a informatiilor de pe orice nivel., insa o actualizare a structurii (modificare nodurilor sau legaturilor) creeaza probleme deosebit de complicate si complexe.
Diagrama de structura a modelului retea se prezinta astfel:
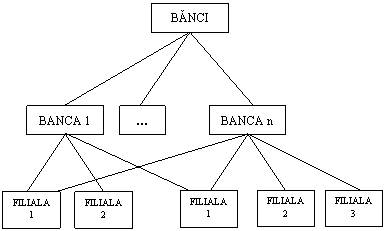
![]() Figura 1.5.2.1 Diagrama de
structura a modelului retea
Figura 1.5.2.1 Diagrama de
structura a modelului retea
In momentul de fata modelul de date retea este foarte rar utilizat pentru baze de date de uz general (care implica operatii de interogare), dar exista unele domenii in care structurarea ca graf a datelor permite o parcurgere eficienta a acestora. De exemplu, majoritatea bazelor de date grafice folosite in modelarea scenelor tridimensionale din realitatea virtuala sunt baze de date retea
1.5.3 Modelul relational
Acest model de date a aparut ca urmare a anomaliilor evidentiate la modelele de date precedente, cum ar fi cele constatate la actualizare, cele referitoare la redundanta informationala, precum si la modul de utilizare eficienta a spatiului.
Modelul relational a fost fundamentat in 1970 de catre E. F. Codd, pe baza teoriei matematice a calculului relational si a relatiilor, conform carora orice structura de date se poate reprezenta sub forma de tabele legate intre ele prin asa-numita informatie de legatura.
Pe langa avantajul unui model de date precis si simplu, sistemele de baze de date relationale mai beneficiaza si de un limbaj de programare unanim recunoscut si acceptat, limbajul SQL (Structured Query Language).
Modelul relational se compune din doua elemente principale, tabele si relatii.
1.5.3.1 Tabele
Tabelele, printr-o structura asemanatoare cu a fisierelor clasice, contin entitatile care se gasesc in baza de date. Fiecare tabel poate fi considerat ca o structura in plan, bidimensionala, care descrie prin entitatile(inregistrarile) pe care le contine o anumita multime de obiecte de acelasi fel.
Entitatile continute intr-un tabel vor avea aceiasi structura, care va reprezenta atributele (caracteristicile, campurile) obiectelor continute de tabel.
Spre exemplificare, oferim in figura 1.5.3.1.1 o baza de date cu doua tabele ANGAJATI si DEPARTAMENTE. In acest exemplu:
ANGAJATI are sapte atribute(campuri), Cod_A, Nume, Prenume, Data_nasterii, Cod_D, Functia, Salariu.
DEPARTAMENTE are trei atribute(campuri) Cod_D, DenumireD si Nr_Angajati.
ANGAJATI are patru inregistrari
DEPARTAMENTE are trei inregistrari.
Tabela ANGAJATI
Cod_A
Nume
Prenume
Data_nasterii
Cod_D
Functie
Salariu
1
Ionescu
Ion
05.01.1967
10
Inginer
5000
2
Popescu
Petre
21.06.1972
20
Maistru
3500
3
Marin
Ana
02.04.1975
10
Secretara
3000
4
Dinca
Nicolae
01.03.1965
30
Inginer
5000
Tabela DEPARTAMENTE
Cod_D
DenumireD
Nr_Angajati
10
CROIT
15
20
CUSUT
20
30
FINISAJ
25
Figura 1.5.3.1.1 Tabele
De exemplu putem din tabelul "ANGAJATI", sa obtinem informatii despre :numele angajatilor, data nasterii, functia si salariul obtinut de acestia, etc., dar nu vom putea sa oferim informatii despre numarul de angajati ai fiecarui departament, deoarece nu pot fi concomitent vizibile tabelele "ANGAJATI" si "DEPARTAMENTE".
1.5.3.2 Relatii
Relatiile, au rolul de a introduce a treia dimensiune in modelul relational, deci de a permite extragerea de informatii din mai multe tabele in acelasi timp(asemanator scarilor care fac legatura intre nivele unei cladiri).
Relatiile se realizeaza intre doua campuri (atribute), care reprezinta acelasi fel de informatii si care apartin celor doua tabele intre care se stabileste o relatie. Dealtfel, datorita acestei dublari a informatiei folosita la realizarea relatiilor, modelul relational are un grad ridicat de redundanta.
Daca ne referim la exemplul prezentat anterior, relatia intre entitatile celor doua tabele DEPARTAMENTE si ANGAJATI se va realiza prin campul(atributul): "Cod_D". In acest fel, se poate acum stii care este denumirea departamentului la care este angajata fiecare persoana, dar informatia folosita pentru aceasta legatura(Cod_D) se va gasi in ambele tabele.
Modelul relational prezentat, va arata ca in figura de mai jos:

Figura 1.5.3.2.1 Modelul relational
1.6 Operatii in modelul relational. Introducere in algebra relationala
In algebra relationala "clasica" toti operanzii si toate rezultatele expresiilor sunt multimi. Deoarece un tabel este o multime, multe dintre aceste operatii sunt preluate din teoria multimilor. Algebra relationala este un set de opt operatii, care preiau unul sau mai multe tabele ca operanzi si produc un nou tabel(virtual) ca rezultat.
Deci o data ce avem creata si incarcata o baza de date, in momentul in care avem de furnizat anumite informatii, prin operatii de algebra relationala se realizeaza un tabel virtual, numai cu datele necesare solicitarii respective. Aceasta reprezinta o operatie de interogare a unei baze de date.
De asemenea prin intermediul celor opt operatii, din punct de vedere teoretic, se poate actualiza o baza de date relationala, si anume se permite:
Adaugarea - introducerea de noi inregistrari in tabele.
Modificarea - schimbarea unor campuri dintr-o inregistrare
Stergerea - eliminarea unei inregistrari.
Operatiile in algebra relationala sunt urmatoarele:
1. Produsul cartezian extins. Produsul cartezian extins, produce un tabel virtual care va avea toate coloanele tabelelor de intrare si un numar de inregistrari suficient pentru a exprima toate combinatiile posibile ale acestor tabele. Este deci cel mai mare tabel care rezulta din combinarea mai multor tabele.
Exemplu:
Tabela 2
Camp4
Camp5
C
1
D
2
E
3
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2

![]()
Produsul cartezian extins
Camp1
Camp2
Camp3
Camp4
Camp5
A
A1
A2
C
1
A
A1
A2
D
2
A
A1
A2
E
3
B
B1
B2
C
1
B
B1
B2
D
2
B
B1
B2
E
3
2. Selectia. Selectia, produce un tabel virtual care in urma unei operatii de filtrare reprezinta un subset orizontal al tabelului originar. Deci dintr-un tabel sunt pastrate numai acele entitati(inregistrari, randuri) care respecta anumite conditii.
Exemplu:
Tabela 2
Camp4
Camp5
C
1
D
2
E
3
Selectie
Camp4
Camp5
D
2
E
3
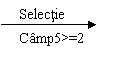
3. Proiectia. Proiectia, produce un tabel virtual care reprezinta un subset vertical al tabelului originar. Deci dintr-un tabel sunt pastrate numai acele coloane(campuri) care ne intereseaza. In urma acestei operatii pot rezulta si campuri virtuale.
Exemplu:
Proiectie
Camp1
Camp2
A
A1
B
B1
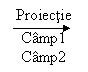 Tabela 1
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2
4. Alaturarea(join). Alaturarea, este un produs cartezian, dar in care sunt pastrate numai inregistrarile care satisfac o anumita conditie. Deci aceasta operatie este formata dintr-un produs cartezian extins urmat de o selectie.
Exemplu:
Tabela 2
Camp4
Camp5
C
1
D
2
E
3
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
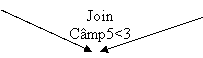 B1
B1
B2
Alaturarea
Camp1
Camp2
Camp3
Camp4
Camp5
A
A1
A2
C
1
A
A1
A2
D
2
B
B1
B2
C
1
B
B1
B2
D
2
5. Reuniunea. Reuniunea, produce un tabel care contine toate inregistrarile celor doua tabele originale, acestea trebuind sa aiba aceleasi campuri. Deci adaugarea unei inregistrari la un tabel este practic o operatie de reuniune.
Exemplu:
Tabela 1
Camp1
Camp2
Camp3
A
![]() A1
A1
A2
B
B1
B2
Tabela 3
Camp1
Camp2
Camp3
C
C1
C2
Reuniune
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2
C
C1
C2
6. Intersectia. Intersectia, reprezinta multimea tuturor inregistrarilor care se gasesc simultan in ambele tabele. Evident pentru a se produce aceasta operatie conditia de la reuniune( ca ambele tabele sa contina aceleasi coloane) trebuie respectata.
Exemplu:
![]()
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2
Tabela 4
Camp1
Camp2
Camp3
C
C1
C2
B
B1
B2
Intersectie
Camp1
Camp2
Camp3
B
B1
B2
7. Diferenta. Diferenta, dintre doua tabele, X si Y, (compatibile pentru reuniune, deci cu aceleasi campuri) consta in multimea inregistrarilor din X care nu sunt in Y.
Exemplu:
Tabela 4
Camp1
Camp2
Camp3
C
C1
C2
B
B1
B2
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2
![]()
Diferenta
Camp1
Camp2
Camp3
A
A1
A2
8. Impartirea. Impartirea, dintre doua tabele, X si Y, duce la crearea unui tabel care contine campurile din X care nu sunt in Y si inregistrarile din X care sunt identice cu cele din Y( in ceea ce priveste coloanele comune). Evident ca exista putine sanse de a aplica un asemenea operator intr-o aplicatie reala.
Exemplu:
![]()
Tabela 1
Camp1
Camp2
Camp3
A
A1
A2
B
B1
B2
Tabela 5
Camp1
Camp4
Camp5
B
X1
X2
C
Y1
Y2
Impartire
Camp2
Camp3
B1
B2
Extinderea algebrei relationale reprezinta modalitatea de implementare practica intr-un SGBD, a algebrei relationale(practic numai a anumitor operatii). In general se realizeaza prin definirea a doua limbaje:
Limbajul de definire a datelor (DDL) care este folosit pentru: crearea de tabele si definirea campurilor acestora, stabilirea cheilor, indexari si sortari, stabilirea relatiilor, asigurarea protectiei datelor.
Limbajul de manipulare a datelor (DML) care se ocupa de: interogarea bazei de date si actualizarea bazei de date.
1.7 Caracteristici ale bazelor de date relationale
Intr-o explicatie simplista, o baza de date poate fi definita ca o colectie de informatii. De exemplu, cartea de telefon este o baza de date, la fel cum este si agenda cu numerele de telefon si catalogul cu fise de la biblioteca. O baza de date relationala este formata din mai multe tabele intre care se stabilesc diferite legaturi(relatii).
1.7.1 Tabela, campul, inregistrarea
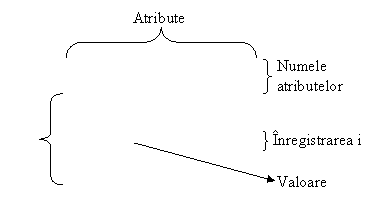
Modelul relational asociaza unei entitati o tabela bidimensionala in care:
coloanele tabelei reprezinta atributele(campuri) entitatii;
liniile (randurile) tabelei reprezinta membrii entitatii.
Fiecare coloana are un nume distinct, prima linie fiind destinata amplasarii acestor nume de atribute. O linie dintr-o tabela se numeste inregistrare.
![]()
A1
A2
A3
An
Vi2
Figura 1.7.1 Elementele unei tabele
La intersectia unui rand cu o coloana se afla valoarea campului.
In modelul relational, pentru ca fiecare entitate sa fie unica este necesar ca cel putin unul dintre campurile tabelului sa aiba o valoare unica.
De asemenea, fiecare tabel va avea in baza de date un nume unic pentru a putea fi identificat. Acesta impreuna si cu alte caracteristici(prezentate in alt capitol) vor reprezenta proprietatile tabelei.
Un tabel este constituit din campuri, care la randul lor au anumite proprietati(caracteristici) printre cele mai semnificative fiind:
Numele(identificatorul) campului;
Tipul de date : numeric, boolean, string, etc.;
Dimensiunea : pentru anumite tipuri de date(de exemplu string) trebuie precizata si lungimea pe care o va avea campul in memoria calculatorului;
Domeniul de valabilitate, adica limitele pe care le iau valorile pentru a fi acceptate intr-un camp.
Exemplu: Tabela DEPARTAMENTE, campul Nr_angajati are tipul de date numeric, byte si trebuie sa fie un numar mai mare ca 0, si eventual mai mic sau egal decat 100. Asta inseamna ca domeniul de valabilitate va fi intre 1 si 100. In acest caz, daca se lucreaza cu:
un fisier clasic cu campul "Nr_Angajati", de fiecare data cand se vor introduce valori in acesta, prin instructiuni de program se va verifica daca data introdusa este in intervalul 1..100;
daca se va lucra cu un camp "Nr_Angajati" al unei tabele, acest lucru nu va mai fi necesar, deoarece respectivul domeniu de valabilitate va fi precizat la descrierea(proprietatile) campului.
1.7.2 Relatii intre tabele
Ceea ce diferentiaza o baza de date relationala de alte aplicatii de gestiune este capacitatea acesteia de a lega doua sau mai multe tabele astfel incat ele sa apara in fata utilizatorului ca o singura tabela.
Pentru a se putea realiza acest lucru este obligatorie existenta unor campuri comune(campuri care sa contina acelasi fel de date) in cele doua tabele care intra in legatura, ceea ce duce totusi la un aspect negativ, si anume la cresterea redundantei si la 'imprastierea' datelor. De exemplu: Campul Cod_D se afla atat in tabela DEPARTAMENTE cat si iin tabela ANGAJATI.
Tabelele care intra intr-o relatie vor fi in "tandemul parinte - copil". Relatia dintre doua tabele se caracterizeaza prin:
tipul relatiei;
tipul de legatura al relatiei.
1.7.2.1 Tipuri de relatii
Pentru explicarea tipurilor de relatii consideram urmatoarea problema: O firma are mai multe gestiuni situate la adrese diferite. In aceste gestiuni se gasesc mai multe produse in stocuri diferite, iar un produs se poate gasi in mai multe gestiuni.
Construim baza de date relationala astfel:
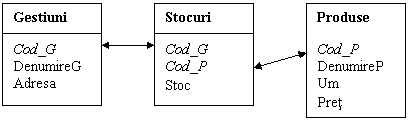 Figura1.7.2.1 Baza de date relationala
Figura1.7.2.1 Baza de date relationala
Urmeaza sa stabilim tipurile de relatii existente intre tabelele construite.
Intre tabelele unei baze de date se pot stabili patru tipuri de relatii, si anume:
1.7.2.1.1 Relatiile one to one(unu la unu)
Relatiile de tipul 1→1 (unu la unu) presupun ca unui membru din colectia A ii corespunde un singur membru din colectia B(figura 1.7.2.1.1.1).
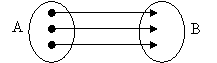
Figura 1.7.2.1.1.1 Relatiile unu la unu
Relatiile de tip unu-la-unu sunt cele mai simple si mai rar folosite, obligand la respectarea urmatoarei reguli: fiecare inregistrare dintr-un tabel corespunde unei singure inregistrari din alt tabel. Astfel de relatii se folosesc pentru a diviza tabelele mari, in doua sau mai multe tabele de dimensiuni mai mici, ceea ce va oferi urmatoarele avantaje:
reducerea timpului de cautare a anumitor date prin separarea informatiilor ce au o frecventa mai redusa de folosire.
imbunatatirea timpului de raspuns la actualizarea datelor in tabele de catre mai multi utilizatori.
cresterea securitatii si a controlului aplicatiei prin separarea intr-un alt tabel a unor informatii cu caracter confidential.
Pentru ca o relatie sa fie one to one, este necesar ca in ambele tabele, campul de legatura sa aiba caracter de unicitate pentru toate inregistrarile tabelei respective.
Exemplu: Relatia dintre tabelele PRODUSE si STOCURI este de tipul one to one daca un produs se gaseste intr-o singura gestiune, o gestiune insa poate contine mai multe produse.
![]()
Tabela PRODUSE Tabela STOCURI
DenumireP
Um
Pret
Cod_P
P1
Kg
10
1
P2
L
15
2
P3
Kg
25
3
P4
L
45
4
Cod_P
Cod_G
Stoc
1
101
10
2
102
30
3
101
50
4
103
20
1.7.2.1.2 Relatiile one to many(unul la mai multi)
Relatiile de tipul 1→ (unu la mai multi) presupun ca unui membru din prima entitate A ii corespund mai multi membri din a doua entitate B(figura 1.7.2.1.2.1).
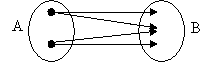
Figura 1.7.2.1.2.1 Relatiile unu la mai multi
Relatiile de tip unu-la-mai multi sunt cele mai frecvente tipuri, realizand legatura intre un rand dintr-un tabel si niciunul, unul, doua sau mai multe randuri din alt tabel. Legatura se realizeaza prin campul cu caracter de unicitate a tabelului parinte si campul corespunzator tabelului copil.
Exemplu: Aceiasi relatie dintre tabelele PRODUSE si STOCURI, realizata prin campul comun Cod_P, va fi o relatie de tipul one to many, daca un produs se poate gasi in mai multe gestiuni.
![]() Tabela PRODUSE
Tabela STOCURI
Tabela PRODUSE
Tabela STOCURI
DenumireP
Um
Pret
Cod_P
P1
Kg
10
![]()
![]()
![]() 1
1
P2
L
15
2
P3
Kg
25
![]() 3
3
P4
L
45
![]()
![]() 4
4
Cod_P
Cod_G
Stoc
1
101
10
1
102
25
1
103
15
3
102
30
4
101
50
4
103
20
De asemenea in tabela virtuala de iesire pentru o inregistrare din tabela parinte(PRODUSE) se pot crea mai multe inregistrari si anume cate inregistrari vor fi in tabela copil(STOCURI) cu aceiasi valoare a campului de legatura ca in tabela parinte. In exemplul de mai sus,
pentru prima inregistrare din tabela parinte se vor genera in tabela virtuala de iesire 3 inregistrari, deoarece exista in tabela copil 3 inregistrari cu aceiasi valoarea a campului de legatura (Cod_P=1),
pentru ultima inregistrare din tabela parinte se vor genera in tabela virtuala de iesire 2 inregistrari(Cod_P=4),
pentru a doua inregistrare din tabela parinte nu se va genera in tabela virtuala de iesire nici o inregistrare, deoarece nu exista in tabela copil nici o inregistrare cu aceiasi valoare a campului de legatura(Cod_P=2).
1.7.2.1.3 Relatiile many to one(mai multi la unu)
Relatiile de tipul →1 (mai multi la unu) presupun ca mai multor membri din prima entitate A le corespunde un membru din a doua entitate B(figura 1.7.2.1.3.1).
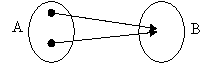
Figura 1.7.2.1.3.1 Relatiile mai multi la unu
Aceste relatii sunt opusele relatiilor one to many. O asemenea relatie este reflexiva daca se poate crea prin inversarea rolurilor entitatilor participante la o relatie one to many. In Microsoft Access toate relatiile sunt reflexive, astfel ca specificarea o singura data a unuia dintre sensuri va asigura functionalitatea relatiei si in celalalt sens.
1.7.2.1.4 Relatiile many to many(mau multi la mai multi)
Relatiile de tipul m→m (multi la multi), in care unui membru din entitatea A ii corespund mai multe date din colectia B si mai multor da-te din colectia A ii corespunde o singura data din colectia B(figura 1.7.2.1.4.1).
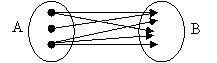
Figura 1.7.2.1.4.1 Relatiile mai multi la mai multi
Relatii de tip multi la multi se mai numesc si relatii de tip retea. O relatie multi la multi se va descompune intotdeauna in doua relatii, o relatie tip unu la multi si respectiv o a doua relatie de tip multi la unu prin intermediul unei entitati de legatura.
Pentru ca o relatie sa fie many to many, este necesar ca in ambele tabele, campul de legatura sa nu aiba caracter de unicitate pentru toate inregistrarile tabelei respective. O asemenea relatie se creeaza prin intermediul unei tabele intermediare care are relatii many to one cu cele doua tabele.
In exemplul prezentat anterior acest rol de tabela intermediara il are tabela "STOCURI", plasata intre tabelele "GESTIUNI" si "PRODUSE". Se observa ca in tabela intermediara vor exista doua campuri de legatura, (Cod_G si Cod_P) cu care se vor realiza cele doua relatii de tip many to one.
Exemplu: Baza de date relationala corespunzatoare exemplului anterior, unde o gestiune are mai multe produse, iar un produs se afla in mai multe gestiuni, stocul de produs stabilindu-se la nivel de gestiune, arata astfel:
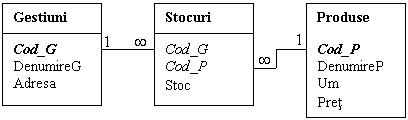
1.7.2.2 Tipurile de legatura ale relatiilor
Tipul de legatura a unei relatii(Join Type), reprezinta o proprietate a relatiei care are efect in ceea ce priveste extragerea de date corelate din tabelele care participa la aceasta.
Problema pe care o rezolva aceasta proprietate este urmatoarea: daca in unul din tabele, exista inregistrari pentru care in campul de relatie contine valori care nu se regasesc in campul corespondent din cealalta tabela, care vor fi inregistrarile care se vor selectiona din ambele tabele?
In functie de inregistrarile care sunt selectate din cele doua tabele care intra in relatie exista doua tipuri de legaturi:
inner join - vor fi selectionate numai acele inregistrari care au campul de legatura egal in ambele tabele.
outer join - vor fi selectionate toate inregistrarile unei tabele iar din cealalta, numai acele inregistrari care au campul de legatura egal in ambele tabele.
1.7.3 Tipuri de chei
Cheia unei tabele reprezinta un ansamblu minim de atribute care identifica o inregistrare dintr-o tabela. Cheia poate fi formata dintr-un singur atribut (cheie simpla) sau din mai multe atribute (cheie compusa). La un moment dat intr-o tabela pot exista mai multe atribute cu proprietatea ca pot identifica o inregistrare, aceste combinatii se numesc chei candidate.
Un tabel, in mod natural trebuie sa contina cel putin o zona (un camp sau o operatie relationala intre mai multe campuri - de ex. reuniune) care sa permita o unicitate a entitatilor. Aceasta zona se numeste cheie primara(principala). Acest lucru se concretizeaza in doua aspecte, si anume: in unicitatea datelor din cheia primara si implicit in inexistenta intr-un tabel a inregistrarilor duplicate.
O cheie primara reprezinta deci un camp care nu contine pentru nici o inregistrare o valoare nula ('NULL' - nu zero) sau duplicata(NULL, este o valoare pe care un camp al unei anumite inregistrari o ia pentru a preciza lipsa de date).
Cand doua tabele sunt asociate(intra in relatie), atunci tabelul parinte trebuie sa aiba un camp special, care sa contina o trimitere precisa la un camp din tabelul subordonat(tabelul copil). Acest lucru se realizeaza prin exportul din tabela parinte a campului cu caracter de unicitate(cheia primara) in tabela copil. Acest camp, din tabela copil, se numeste cheie externa(staina).
1.7.4 Principii de normalizare a bazelor de date relationale
La proiectarea structurii unei baze de date relationale trebuie stabilite in primul rand tabelele in care vor fi memorate datele si asocierile dintre tabele. Acestea sunt stabilite intr-o forma initiala, dupa care, prin rafinare succesiva se ajunge la forma definitiva. Acestei structuri initiale ii sunt aplicate un set de reguli care reprezinta pasii de obtinere a unei baze de date normalizate. Daca o baza de date nu este normalizata ea nu poate fi utilizata cu un maxim de eficienta.
Normalizarea este procesul reversibil de transformare a unei relatii in relatii de structura mai simpla. (Procesul este reversibil in sensul ca nici o informatie nu este pierduta in timpul transformarii). Scopul normalizarii este de a suprima redundantele logice, de a evita anomaliile la reactualizare si rezolvarea problemei reconexiunii.
Astfel, intr-o tabela fiecare element(intersectia unui rand cu o coloana, uneori se mai foloseste si termenul de celula), trebuie sa aiba o singura valoare, denumita valoare atomica. De asemenea prin normalizare se vor elimina informatiile duplicate din tabele iar schema bazei de date trebuie creata astfel incat sa permita modificari ale acesteia.
Normalizarea unei baze de date, este realizata in 5 pasi dintre care primii trei sunt mai importanti, si anume:
FN1. Inregistrarile sa contina pentru campuri numai valori atomice (de exemplu, nu poate exista un camp denumit "Preț" in care sa plasam o lista de preturi). si sa nu contina grupuri care se repeta.
FN2. Datele din campurile care nu sunt chei, sa depinda de cheia primara. Aceasta regula se aplica cand se utilizeaza o cheie primara care contine mai multe coloane. De exemplu, sa presupunem ca avem un tabel care contine urmatoarele coloane, dintre care Nr_Comanda si Cod_Produs alcatuiesc cheia primara compusa:
. Nr_Comanda (cheie primara)
. Cod_Produs (cheie primara)
. NumeProdus
Acest tabel incalca a doua forma normala, deoarece NumeProdus depinde de Cod_Produs, dar nu si de Nr_Comanda, asadar nu depinde de intreaga cheie primara. NumeProdus trebuie eliminat din tabel, el apartine de alt tabel (Produse).
FN3. Toate campurile sa fie independente unul fata de altul. Un alt mod de a spune aste este ca fiecare coloana care nu este cheie trebuie sa depinda de intreaga cheie primara si numai de cheia primara. De exemplu, sa presupunem ca avem un tabel care contine urmatoarele coloane:
. Cod_Produs (cheie primara)
. NumeP
. Pret
. Reducere
Acest tabel incalca a treia forma normala, deoarece o coloana care nu este cheie, Reducere, depinde de alta coloana care nu este cheie, Pret. Independența coloanelor inseamna ca se poate modifica orice coloana care nu este cheie fara a afecta alte coloane. Daca se modifica o valoare din campul Pret, se modifica in mod corespunzator Reducere(care reprezinta un procent din pret), asadar incalcandu-se regula.
FN4. Intre tabele sa nu existe entitati independente intre care sa existe relatii de tipul many to many.
FN5. O tabela initiala, care a fost descompusa in mai multe tabele, sa poate fi refacuta.
In proiectarea bazelor de date relationale, prin procesul de normalizare a tabelelor care contin datele primare ale obiectului supus modelarii, se produc:
eliminarea din tabele a informatiilor care se repeta prin extragerea acestora si mutarea in noi tabele, care contin inregistrari cu valori unice ale datelor;
repartizarea in tabele numai a campurilor ce depind de cheia primara;
eliminarea campurilor care pot fi obtinute prin operatii ai caror operanzi sunt alte campuri;
stabilirea relatiilor intre tabelele cu valori comune ale campurilor de date;
introducerea de tabele intermediare in cazul relatiilor many to many.
1.7.5 Integritatea datelor
Restrictiile de integritate ale modelului relational reprezinta cerinte pe care trebuie sa le indeplineasca datele din cadrul bazei de date pentru a putea fi considerate corecte si coerente in raport cu lumea reala pe care o reflecta. Daca o baza de date nu respecta aceste cerinte, ea nu poate fi utilizata cu un maxim de eficienta.
Principalele tipuri de integritate a datelor unui model relational sunt:
Integritatea existentiala, impune ca intotdeauna intr-o tabela sa nu existe doua inregistrari identice. Acest lucru se realizeaza de la sine daca se defineste o cheie primara pentru tabela respectiva.
Integritatea referentiala, impune ca orice valoare dintr-o cheie externa a unei tabele copil sa se regaseasca printre valorile pe care le ia cheia de legatura din tabelul parinte asociat.
Integritatea de domeniu, impune pentru un camp care are stabilit un anumit domeniu, sa nu fie acceptate date care sunt in afara acestuia.
1.7.6 Sortare si indexare.
Cea mai utilizata operatie care se efectueaza pe tabelele unei baze de date este sortarea.
Sortarea reprezinta operatia prin care inregistrarile unei tabele sunt aranjate in ordine ascendenta sau descendenta dupa valorile pe care le ia un camp, denumit cheie de sortare.
Exista posibilitatea ca dupa ce se sorteaza toate inregistrarile unei tabele dupa un camp, numai pentru acele inregistrari in care campul respectiv are valorile egale sa se procedeze la o noua sortare dupa alt camp. In acest caz se va produce o sortare dupa mai multe chei de sortare.
Pentru a se putea realiza operatiile relationale cu tabelele de cele mai multe ori acestea trebuiesc in prealabil sortate. Realizarea sortarii se poate efectua in doua feluri, fizic sau logic(prin intermediul indecsilor)
Sortarea fizica necesita aranjarea efectiva pe disc a inregistrarilor in ordinea dorita dupa valorile cheii(cheilor) de sortare. Ea este o operatie care consuma foarte mult timp si memorie.
Sortarea logica nu modifica pozitia inregistrarilor de pe disc, ci ea permite numai regasirea acestora in ordinea ascendenta sau descendenta pe care o iau valorile din cheia(cheile) de sortare.
Aceasta operatie se face in prealabil prin atasarea la campul(campurile) dupa care se face sortarea a unei tabele de indecsi. Indexarea reprezinta operatia de atasare a tabelelor de indecsi la un camp, care va deveni indexat. Indecsii sunt niste tabele de dimensiuni reduse, care contin 2 campuri, si anume cheia de sortare(indexul) si adresa fizica a inregistrarii corespunzatoare.
Sortarea efectiva a acestui tabel de indecsi de dimensiuni reduse, care consuma foarte putin timp, da posibilitatea dupa aceea a accesarii inregistrarilor tabelei bazei de date in ordine crescatoare sau descrescatoare dupa cheia de indexare, fara ca acestora sa li se modifice pozitia de pe disc.
In felul acesta operatia de sortare logica a tabelei originale prin intermediul indexarii prealabile a campului ce este cheie de sortare se va efectua in conditiile unui consum minim de timp si memorie.
Indexarea este utilizata si la alte operatii in afara de sortare. Astfel selectia inregistrarilor care au o anumita valoare pentru un camp, se realizeaza de zeci de ori mai rapid daca acest camp este indexat.
1.8. Exemple de sisteme de gestiune a bazelor de date relationale
1. Oracle. Este realizat de firma Oracle Corporation USA. Sistemul este complet relational, robust, se bazeaza pe SQL standard extins. Arhitectura sistemului este client/server, are baze de date Internet si modul de optimizare a regasirii.
2. DB2. Este realizat de firma IBM. Sistemul respecta teoria relationala, este robust si se bazeaza pe SQL standard. Permite lucrul distribuit si are modul de optimizare a regasirii.
3. Progress. Este realizat de firma Progress Software. Are limbaj propriu (Progress 4GL) dar suporta si SQL. Ruleaza pe o gama larga de calculatoare sub diferite sisteme de operare.
4. SQL Server. Este sistemul de gestiune a bazelor de date relationale dezvoltat de firma Microsoft pentru sistemele de operare Windows. In toate versiunile sistemul SQL Server suporta complet standardul SQL2, cu implementarea performanta a trasaturilor avansate de stocare si prelucrare a datelor
5. Visual FoxPro. Este realizat de firma Microsoft. Are un limbaj procedural propriu foarte puternic, o extensie orientata obiect, programare vizuala si nucleu extins de SQL.
6. Paradox. Este realizat de firma Borland. Are limbaj procedural propriu (PAL) si suporta SQL
7. Access. Este realizat de firma Microsoft. Se bazeaza pe SQL, are limbajul procedural gazda (Basic Access) si instrumente de dezvoltare. Microsoft Access este unul din cele mai cunoscute sisteme de gestiune a bazelor de date relationale pe platforme de calculatoare personale. MS Access dispune de un sistem de control al bazei de date si o interfata grafica pentru interactiunea cu utilizatorul. Aplicatiile de baze de date in MS Access se pot dezvolta cu multa usurinta datorita generatoarelor de aplicatii (Wizards) care permit proiectarea vizuala a bazelor de date si a formularelor (forms) pentru interfetele grafice. MS Access este folosit in special pentru aplicatii personale sau pentru mici afaceri