|
|
|
|
CONCEPTE UTILIZATE iN STUDIUL BD sI AL SGBD
Organizarea datelor in fisiere, desi este destul de utilizata, are o serie de neajunsuri care limiteaza eficienta si eficacitatea aplicatiilor utilizator. Dintre acestea amintim redundanta ridicata a datelor, lipsa integrarii datelor, dependenta datelor fata de programele de aplicatii, costul ridicat de intretinere etc.
Redundanta ridicata a datelor. Fisiere de date independente contin o multime de date care se repeta. Aceleasi date (exemplu: nume furnizor, adresa furnizor, cont la banca, etc.) sunt inregistrate si stocate in mai multe fisiere ceea ce reclama programe distincte pentru actualizarea fiecarui fisier. In plus duplicarea datelor conduce la un consum mare de memorie si incoerenta la trecerea datelor stocate dintr-un fisier in altul.
Sintetic efectele imediate ale acestui neajuns sunt:
gestionarea complexa a datelor;
actualizarea greoaie a datelor;
monopolizarea inutila a spatiului de memorie.
Neintegrarea datelor. Dispersia datelor in diverse fisiere independente complica accesul utilizatorilor la informatiile cerute ad-hoc, necesitand crearea de programe particulare pentru extragerea datelor solicitate. In lipsa acestor programe, pentru obtinerea informatiilor dorite utilizatorul procedeaza la extragerea manuala.
Dependenta datelor de programe. Organizarea fisierelor, adresarea fizica in memorie si programele de aplicatii folosite pentru accesarea fisierelor sunt interdependente. Astfel, schimbarile legate de dispunerea pe suportul de memorie, structura datelor si modificarea inregistrarilor unui fisier presupun modificari in toate programele in care este referit fisierul respectiv. Intretinerea acestor programe este dificila putand genera incoerente in fisierele de date. Incoerenta si lipsa de integritate sunt extrem de dificil de corectat deoarece nu exista un "dictionar" central pentru urmarirea definirii datelor.
Costul de intretinere. Exploatarea fisierelor independente presupune un cost ridicat atat in ceea ce priveste resursele informatice (hardware si software) cat si cele legate de personalul utilizat.
Toate aceste probleme care apar in sistemul ce prelucreaza fisiere isi gasesc rezolvarea prin folosirea bazelor de date si a sistemelor de gestiune a bazelor de date. Datele stocate in baze de date sunt independente atat fata de programele de aplicatii care le folosesc, cat si fata de tipul de memorie utilizat.
Sintetizand cele de mai sus rezulta ca principalele "beneficii" ale bazelor de date constau in[1]
integrarea in aceeasi structura a tuturor datelor pertinente ale unui sistem;
gestionarea acestor date printr-un soft specializat (SGBD);
oferirea unei vederi partiale asupra ansamblului de date, necesara fiecarui utilizator;
asigurarea partajarii datelor intre diferiti utilizatori.
Baza de date reprezinta un ansamblu integrat de inregistrari sau de fisiere reunite si structurate in mod logic. In felul acesta datele stocate anterior in fisiere independente /distincte sunt concentrate intr-un fond comun de inregistrari cu posibilitatea utilizarii lor in numeroase aplicatii.
Conceptul de baza de date a aparut in 1964 in cadrul primului raport CODASYL prezentat la lucrarile unei Conferinte pe probleme de limbaje de gestiune a datelor "Development and Management of Computer - centered data-base". La aceasta conferinta a fost lansata ideea organizarii datelor prin intermediul unui fisier de descriere globala numit dictionar de date care are menirea de a asigura independenta programelor fata de date si a datelor fata de programe[2]
Accesul utilizatorului la informatiile despre structura unei anumite baze de date se realizeaza prin intermediul unui software de aplicatii care ofera un ajutor apreciabil gestiunii datelor, in general, si bazelor comune de date, in special, numit dictionar de date.
Prin intermediul dictionarului de date, dupa caz, sistemul stocheaza informatii referitoare la:
relatiile bazei de date (denumire, descriere etc.);
atributele relatiei (denumire, domenii, tip, chei primare si secundare);
utilizatorii care au drepturi de acces la o anumita relatie;
optimizarea bazei de date (prin fisiere index, tehnica clustering etc.).
In principal, un dictionar indeplineste urmatoarele functii:
definirea si gestionarea datelor elementare ale intreprinderii (cod, denumire, atribute, reprezentare etc.);
definirea si gestionarea ansamblurilor de date;
definirea si gestionarea relatiilor, de dependenta sau ierarhice, dintre date;
descrierea utilizarii datelor din trei puncte de vedere:
administrativ: care sunt posturile de lucru ce vor apela datele si care va fi utilizarea acestor date?
logic: care sunt fisierele sau bazele de date in care intra elementele descrise ?;
organic: in care unitati de prelucrare vor fi utilizate elementele descrise?
Legatura dintre aceste functii este prezentata in figura nr. 4.1.

Fig.4.1 Elementele dictionarului de date
(Prelucrare dupa Lesca, H., Peaucelle, J. L., Elements d'informatique applique a la gestion, Edition Dalloz, Paris, 1988, p. 139)
Abordarea corecta a bazelor de date presupune si tratarea urmatoarelor elemente: entitatea (articol, inregistrare logica), atributele (caracteristica, camp) si valoarea /realizare[3]
Prin entitate se intelege un obiect concret sau abstract (operatie economica, mijloc economic etc.) reprezentat prin proprietatile sau insusirile sale. Orice proprietate poate fi exprimata printr-o pereche atribut-valoare sau caracteristica-realizare. O entitate este identificata printr-un nume si cuprinde, in general, mai multe valori sau realizari.
Atributul are rolul de a descrie insusirile sau proprietatile obiectului stabilind natura valorilor pe care acesta le poate lua.
Valoarea reprezinta marimea ce se atribuie fiecarei caracteristici din cadrul unei entitati. Reunite aceste elemente sunt prezentate intr-un exemplu in tabelul nr. 4.1.
Tabelul nr. 4.1 Elemente specifice bazelor de date
Entitate
Caracteristici (atribute)
Realizari (valori)
PRODUS
Cod produs
Denumire produs
Unitate de masura
Pret unitar
Cantitate
Valoare
Nr. Factura
Data receptie
11112
Pantofi
Per
350000
100
35000000
2452
11116
Ghete
Per
550000
100
55000000
2147
18-12-1999
O baza de date trebuie sa satisfaca cinci conditii esentiale[4]
1. buna reprezentare a realitatii inconjuratoare; o baza de date trebuie sa ofere intotdeauna o imagine fidela a realitatii prin informatii fiabile si actualizate;
2. non-redundanta informatiei; informatia continuta in baza de date trebuie sa fie unica din punct de vedere semantic si fizic;
3. independenta datelor fata de prelucrari; datele constituie imaginea fidela a lumii reale, programele de aplicatii trebuind sa fie concepute in raport cu aceasta structura a datelor;
4. securitatea si confidentialitatea datelor; securitatea datelor trebuie asigurata prin proceduri fizice, iar confidentialitatea prin proceduri care sa impiedice accesul utilizatorilor neautorizati;
5. performante in exploatare; orice cerere de prelucrare trebuie sa fie satisfacuta intr-un timp convenabil utilizatorului, ceea ce presupune folosirea unor tehnici de optimizare pentru reducerea timpului de prelucrare.
O baza de date special conceputa prin agregarea tuturor datelor unei intreprinderi in vederea sprijinirii procesului de fundamentare a deciziilor constituie asa numitul depozit de date - data warehouse.
Ideea depozitelor de date nu este recenta, ea s-a conturat si dezvoltat in anii '90. William Inmon este cel care defineste pentru prima oara termenul de data warehose.
Depozitul de date poate fi considerat ca un sistem de baze de date special conceput pentru analiza datelor si fundamentarea deciziilor prin agregarea tuturor datelor intreprinderii. Depozitele de date sunt asadar, enciclopedii informationale in care datele sunt introduse continuu, utilizatorul putandu-le accesa in functie de necesitati.
In depozitele de date se memoreaza urmatoarele tipuri de date:
date curente din sistemele operationale /tranzactionale;
date de detaliu privind perioadele precedente (date din arhive);
date agregate necesare sprijinirii procesului decizional pe toate nivelurile manageriale preluate din surse interne si externe (baze de date publice, sondaje, date de prognoza etc.);
metadate care asigura exploatarea depozitelor de date prin reguli de extragere si conversie, reguli de agregare etc.
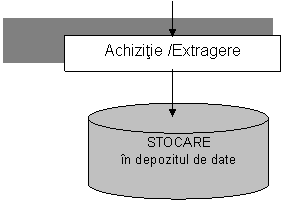
Spre deosebire de colectiile de date utilizate in sistemul operational - orientate spre optimizarea si siguranta procesarii datelor, datele din depozitul de date sunt organizate intr-o maniera care sa permita analiza lor. Rezulta ca depozitul de date acopera un orizont temporal mai mare, contine atat date interne cat si date externe si este optimizat pentru a raspunde complexelor interogari ale unei game diversificate de utilizatori. Schematizat, fluxul datelor intr-un depozit de date este prezentat in figura nr. 4.2.
In cazul depozitelor de date, prelucrarile /exploatarile (data mining) sunt bazate pe modele performante de selectare si agregare a datelor continute.
Practica ofera trei solutii de organizare a depozitelor de date[5]
la nivelul entitatii social-economice (data warehouse);
la nivelul unei structuri functionale: filiala, departament, serviciu, birou (data marts);
la nivelul evenimentelor elementare (tranzactionale).
In implementarea unui depozit de date pot fi folosite mai multe variante:
implementarea unui sistem descentralizat in care datele sunt pastrate in unitati independente (data marts); aceste unitati contin date relevante pentru un anumit aspect al operatiunilor derulate in entitatea social-economica;
implementarea unei surse de date unice la care au acces utilizatorii din toate structurile functionale;
implementarea unei surse de date centralizate la nivelul entitatii social-economice cu existenta unor unitati dependente (dependent data marts) care prezinta subseturi ale datelor (din depozitul central de date) ce au fost selectate si organizate pe domenii de aplicatii.


Baze de date
operationale
Stergere Prelucrare
![]()
![]() Arhivare (data
mining)
Arhivare (data
mining)
Agregare
Fig. nr. 4.2 Fluxul datelor intr-un depozit de date
Utilizarea depozitelor se concretizeaza in obtinerea unor rapoarte (la cerere sau pe baza unui abonament cu o anumita periodicitate), extragerea unor date pentru a fi utilizate in aplicatii de birotica (programe de calcul tabelar, procesare de texte etc.), dar mai ales pentru realizarea unor aplicatii specializate de analiza a datelor.
Principalul inconvenient al depozitului de date este dimensiunea sa enorma, de ordinul giga sau teraoctetilor, datorata inmagazinarii datelor detaliate la cel mai analitic nivel.
Segmentul de piata legat de depozitele de date are o rata anuala de crestere de circa 35%.
Pentru a putea fi exploatata de catre utilizatori, o baza de date trebuie sa aiba asociat un set de programe care sa permita exploatarea rationala a datelor continute. Este vorba despre sistemul de gestiune a bazelor de date, denumit generic SGBD.
SGBD-ul este definit ca un ansamblu coordonat de programe care permite descrierea, memorarea, manipularea, interogarea si tratarea datelor continute intr-o baza de date. El trebuie, de asemenea, sa asigure securitatea si confidentialitatea datelor intr-un mediu multi-utilizator[6]
Pentru a-si indeplini aceste functii SGBD-ul interactioneaza cu structura bazei de date, sistemul de calcul, sistemul de operare, programele de aplicatii si utilizatorii constituindu-se banca de date. Se pot organiza banci de date in toate sferele de activitate: baze de date bibliografice, de documentare statistica, evidente finanfiar-contabile si bancare, diagnosticare si informare medicala, rezervarea tichetelor de calatorie si a locurilor in statiunile turistice etc.
Modele conceptuale de structurare si organizare a datelor in baze de date
Pentru descrierea structurii datelor unei baze de date si a relatiilor dintre acestea sunt folosite procedee formale, concretizate in modele conceptuale. Acestea se particularizeaza prin terminologia utilizata si prin relatiile dintre date.
Tipuri de relatii si structuri de reprezentare a relatiilor in cadrul unei baze de date
Entitatile aceluiasi sistem informational sunt rareori izolate unele de altele, ele antrenand, cel mai adesea, legaturi sau relatii. Intre datele diverselor tipuri de entitati pot exista doua categorii de legaturi sau relatii. Prima priveste relatiile dintre datele apartinatoare aceleiasi entitati, iar a doua se refera la relatiile dintre mai multe entitati care pot fi si de tipuri diferite.
Dupa numarul entitatilor care intra in legatura, relatiile pot fi binare si n-are.
Relatiile binare presupun existenta unui domeniu, a unui codomeniu si a unei corespondente intre entitatile acestora. In practica bazelor de date se disting patru tipuri de relatii binare: 1-1, 1-n, n-1, n-n.
In relatiile 1-1 (una-la-una) unei realizari din domeniu ii corespunde o realizare si numai una din codomeniu (figura nr. 4.4).
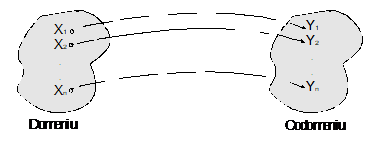
Fig. nr. 4.4 Relatia de tip 1-1
In relatiile 1-n (una-la-mai-multe) unei realizari din domeniu ii corespund 0, una sau mai multe realizari din codomeniu (figura nr. 4.5).

Fig. nr. 4.5 Relatii de tip 1-n
In relatiile n-1 (mai-multe-la-una) mai multe inregistrari din domeniu corespund unei realizari din codomeniu. (figura nr. 4.6).
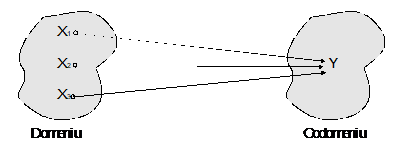
Fig. nr. 4.6 Relatia n-1
In relatiile n-m (mai-multe-la-mai-multe) unei realizari din domeniu ii corespund 0, una sau mai multe realizari din codomeniu, iar unei realizari din codomeniu ii corespund 0, una sau mai multe realizari din domeniu (figura nr. 4.7).
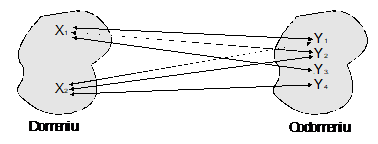
Fig. nr. 4.7 Relatia n-m
Relatiile n-are presupun existenta unei interdependente logice intre realizarile mai multor entitati.
Mecanismul de selectie si de identificare a componentelor unei baze de date presupune existenta unei structuri de date. Concret o structura de date reprezinta o colectie de date intre care s-au stabilit anumite relatii. Structurile de date care au aceeasi organizare si sunt supuse prelucrarilor cu un grup de operatori de baza cu o semantica predefinita formeaza un anumit tip de structura.
Niveluri de abstractizare a datelor
Spre deosebire de fisiere in care datele erau organizate pe doua niveluri logic si fizic, pentru proiectarea bazelor de date sunt definite trei niveluri de abstractizare: conceptual, logic si fizic.
Nivelul conceptual permite specificarea regulilor de gestiune pentru acoperirea intregii structuri a datelor si satisfacerea cerintelor tuturor utilizatorilor concomitent cu asigurarea unei redundante minime a datelor. Modelele utilizate sunt de natura semantica si nu tin seama de tehnicile ce vor fi utilizate la darea in exploatare a bazei de date.
Inainte de a realiza integrarea in schema conceptuala, pe acest nivel se procedeaza la elaborarea de modele partiale sau vederi externe de date.
Nivelul logic permite descrierea structurii inregistrarilor logice in cadrul colectiilor, adica a modului in care utilizatorii isi creeaza structurile de date pentru propriile aplicatii. Aceste structuri sunt orientate spre o clasa de solutii fiind mai "informatice" si tin cont de tehnicile de optimizare folosite (cai de acces, volume, frecventa)[7]
Nivelul fizic permite descrierea structurii sub care colectiile de date se regasesc efectiv pe suprafata de memorare (memorie interna si/sau externa). La acest nivel se va trece de la descrierea logica la o descriere ce va utiliza concret posibilitatile sistemului de gestiune a bazelor de date.
Dintr-o alta perspectiva nivelul conceptual anterior poate fi divizat intr-un nivel extern pe care se definesc vederile externe propuse de utilizatori si un nivel conceptual care da viziunea globala sau de ansamblu. In acelasi timp este posibila regruparea nivelului logic si fizic intr-un nivel intern.
Legatura dintre aceste niveluri este prezentata in figura nr. 4.8.
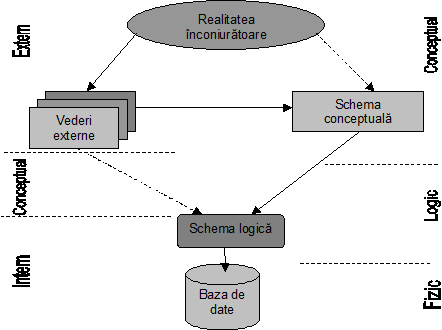
Fig. nr. 4.8. Niveluri de abstractizare a datelor
Modele de organizare a datelor in bazele de date
Un model este un ansamblu de concepte ce permite stabilirea reprezentarii modului de percepere a lumii inconjuratoare. Acesta poseda, in general, un formalism grafic de reprezentare. In practica sunt disponibile doua clase de modele:
1. modele care privesc reprezentarea la nivel conceptual, raspunzand preocuparilor semantice (modelul Entitate-Asociatie, modelul binar, modelul retea semantica etc.);
2. modele care privesc memorarea la nivel logic si fizic raspunzand preocuparilor informatice propriu-zise (modelul relational, modelul retea si modelul ierarhic).
Modelele de date ajuta la conceperea fizica a unei baze de date, inclusiv elaborarea programelor de aplicatii, prin intermediul unor cadre logice numite scheme si sub-scheme.
Schema reprezinta o vedere logica globala a relatiilor dintre datele unei baze, in timp ce sub-schema este o vedere logica a relatiilor necesare intre date pentru sustinerea anumitor programe de aplicatii prin care utilizatorii vor avea acces la aceasta baza de date. Simplificat, legaturile dintre vederile logice, fizice si interfata logica a unui sistem de prelucrare organizat pe baza de date, in cadrul unei banci este prezentat in figura nr.4.9:
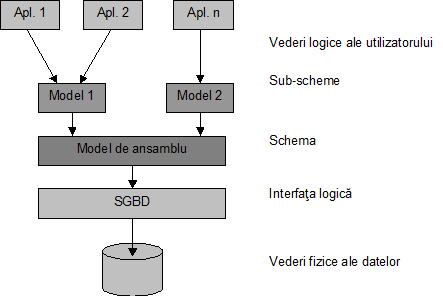
Fig. nr. 4.9 Legaturile dintre vederile logice, fizice si interfata sistem
Modelul ierarhic
Modelul ierarhic este primul model utilizat pentru organizarea datelor in baze de date. El se bazeaza pe structura arborescenta si pe relatiile 1-1 si 1-n, prezentandu-se sub forma unui arbore, in care se regasesc pe un prim nivel - radacina (nod-parinte), iar pe nivelurile urmatoare diferite elemente subordonate (noduri-copil).
Nodul-parinte poate avea subordonate mai multe noduri-copil in timp ce un nod-copil nu poate avea decat un singur parinte. Rezulta ca relatia parinte-copil poate fi de tip 1-n, iar relatia copil parinte poate fi doar de tip 1-1. Acest model asigura organizarea datelor pe orice tip de suport magnetic si reducerea timpului de acces la inregistrari.
Modelul ierarhic are o serie de limite, in special in operatiile de actualizare cand adaugarea de noi inregistrari - cu exceptia celor din colectia de date radacina - se poate efectua numai cu specificarea colectiilor de date superioare, iar stergerea unei inregistrari duce la eliminarea fizica a tuturor inregistrarilor subordonate. In figura nr. 4.10 este prezentat modelul ierarhic.
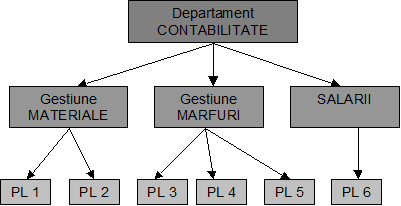
Fig. nr. 4.10 Modelul ierarhic
Din acest exemplu rezulta ca departamentul CONTABILITATE (nod-parinte) este constituit din mai multe aplicatii si posturi de lucru (noduri-copil) in timp ce fiecare nod-copil este subordonat unui singur nod-parinte.
Modelul retea
Modelul retea elimina redundantele specifice modelului ierarhic si se bazeaza pe structurile retea si pe relatiile de tip 1-1, 1-n si n-m. Caracteristica principala a acestui model este ca accepta ca orice colectie de date sa se situeze pe nivelul 1, astfel fiind permis accesul direct la realizarile colectiilor superioare -operatie imposibila in modelul ierarhic. In plus, prin acest model este permisa reprezentarea unica a realizarilor in baza de date.
Legaturile fizice pe suport sunt asigurate prin intermediul unor caracteristici care exprima pointer-ul (adresa de pe suport) realizarii superioare sau al realizarii subordonate. Astfel, reteaua este un graf orientat alcatuit din noduri conectate prin arce. Nodurile corespund tipurilor de inregistrare, iar arcele pointer-ilor. In felul acesta este permisa introducerea inregistrarilor artificiale pentru a reprezenta legaturile n-are (n>2) - vezi figura nr. 4.11.
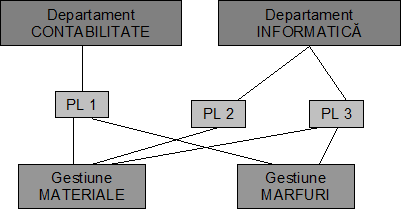
Fig. nr. 4.11 Modelul retea
Dupa cum se observa din figura nr. 4.11 modelul admite relatii de tip n-m, ceea ce are ca efect reducerea redundantei datelor. Modelele ierarhic si retea nu permit realizarea unei independente logice satisfacatoare intre date si programe, deoarece relatiile dintre date exista si sunt referite in programele de aplicatii.
Modelul relational
Modelul relational a fost fundamentat in 1970, de E.F. Codd si se bazeaza pe teoria matematica a relatiilor si pe calculul relational. Ideea unui model ansamblist a datelor a fost lansata inca din 1968 de catre Childs D.F. care arata ca orice structura de date poate fi reprezentata sub forma de tabele (una sau mai multe) in interiorul carora trebuie sa existe si informatie de legatura[8] Acest model va fi dezvoltat in capitolul 5.
Modelul Entitate-Asociatie (E-A)
Acest model a fost introdus in 1976 de catre cercetatorul american Chen care a avut ca obiectiv crearea unui model care sa permita "o viziune unificata, globala asupra datelor"[9]. Este un model semantic de date, simplu si atractiv datorita reprezentarii sale grafice, fiind utilizat in mai multe metode de analiza si proiectare (MERISE, AXIAL etc.) si dispunand de mai multe extensii. Modelul opereaza cu urmatoarele concepte de baza: atribut, entitate /proprietate, entitate-tip, asociatie.
Atributul reprezinta o informatie elementara definita pe un domeniu.
Entitatea este considerata un obiect concret sau abstract din "lumea observata" avand o existenta proprie, care poate fi identificat si descris printr-un ansamblu de atribute, independent de alte obiecte.
Literatura de specialitate nu ofera insa o definitie unanim acceptata pentru acest concept, fiind totusi subliniate urmatoarele caracteristici[10]
entitate are o existenta proprie;
este abstracta sau concreta;
apartine unei familii de obiecte de aceeasi natura (clasa sau entitate tip);
intr-o entitate tip (denumita si clasa) fiecare membru (denumit realizarea entitatii) este definit fara ambiguitati.
Clasa de entitati (denumita si entitate tip) reprezinta un ansamblu de entitati de aceeasi natura, deci cu aceleasi atribute, fiecare entitate fiind identificata intr-o maniera unica. Numarul de atribute este stabilit de catre proiectant. Reprezentarea unei clase de entitati se realizeaza printr-un nume si printr-un ansamblu de atribute de descriere.
De exemplu, clasa ANGAJAT se defineste prin atributele: Numar marca, Nume, Prenume, Functie, Data angajarii si se poate reprezenta astfel:
Angajat
Numar marca
Nume
Prenume
Functie
Data angajarii
Identificarea unica a unei clase de entitati se realizeaza cu ajutorul unuia sau a mai multor atribute permitandu-se distingerea intr-o maniera unica a fiecareia dintre realizarile clasei. In exemplul de mai sus identificarea unica a fiecarui angajat poate fi realizata prin Numar marca sau prin Nume.
Asociatia (relatia) reprezinta o legatura semantica definita intre doua sau mai multe entitati. Asociatiile de acelasi tip formeaza o clasa de asociatii. O asociatie se caracterizeaza prin dimensiune si cardinalitate.
Dimensiunea unei asociatii reprezinta numarul de clase de entitati implicate intr-o clasa de asociatii. Clasele de asociatii pot fi:
unare - relatiile se stabilesc intre entitatile aceleiasi clase;
binare - relatiile se stabilesc intre entitatile aflate in doua clase diferite;
n-are - relatiile se stabilesc intre n clase de entitati.
Cardinalitatea reprezinta un cuplu de valori (M:N) desemnand numarul (minim si maxim) de entitati din fiecare clasa ce pot fi implicate intr-o asociatie. Cuplul de valori (M:N) specifica pe de o parte daca asociatia este partiala (M=0) sau totala (M=1) si, pe de alta parte, daca relatia reprezinta o functie monovaloare (N=1) sau multivaloare (N>1). Pot exista 4 tipuri de cardinalitati (tabelul nr. 3.2).
Tabelul nr. 3.2 Tipuri de cardinalitati
Cardinalitate minimala
Cardinalitate maximala
0
1
0
1
1
1
N
N
Utilizarea acestui model este in mare parte intuitiv. El nu este un model teoretic de reprezentare, ci mai curand o interfata prietenoasa de schitare a structurii datelor. Adesea este utilizat pentru ilustrarea grafica a modelului relational.
Absenta limbajului de manipulare a datelor bine formalizat si adaptat a antrenat numeroase propuneri, preferinta mergand spre limbajele relationale. Ratiunea principala este relativa usurinta de transformare a modelului E-A in model relational. Practic se construieste o schema E-A care se transforma in schema relationala. In felul acesta se combina simplitatea de descriere a primului model cu puterea limbajului celui de al doilea model.
In cadrul modelului E-A, descrierea textuala a entitatilor si a relatiilor lor este uneori greoaie. In practica se apeleaza la o reprezentare mai comoda sub forma unor scheme de sinteza ce faciliteaza comunicarea, cunoscute sub denumirea de formalisme. Principalele formalisme sunt Merise, Chen, Ross, Case*Methode, Perkinson etc. Prezentam in continuare doar formalismele Merise si Chen.
Formalismul Merise
Asa cum rezulta din figura nr. 4.12 simbolurile grafice pentru formalismul Merise sunt:
dreptunghiul - pentru reprezentarea claselor de entitati. In interior se specifica un nume (pentru identificarea entitatilor), sub care sunt enumerate atributele;
elipsa - pentru reprezentarea claselor de asociatii. In interiorul elipsei se inscrie numele clasei, sub care pot aparea eventualele atribute;
liniile - pentru unirea simbolurilor precedente; pe aceste linii se inscriu cifre care exprima cardinalitatile claselor de asociatii.
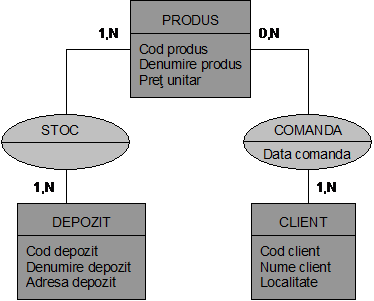
Fig. nr. 4.12 Formalismul grafic Merise
Se observa ca o asociatie este reprezentata printr-o elipsa, unind entitatile implicate. Fiecare legatura semnifica relatia dintre entitate si asociatie. Langa entitati se inscriu cardinalitatile, adica numerele maxime si minime de realizari posibile.
Din exemplul nostru din figura nr. 4.12 rezulta ca entitatea PRODUS are cardinalitatea 0,N ceea ce inseamna ca un produs poate sa nu fie comandat (valoarea 0) sau sa apara in una, doua sau N comenzi.
Formalismul grafic Chen
In notatia grafica Chen sunt folosite urmatoarele simboluri:
dreptunghiurile - pentru clase de entitati. In interior se specifica identificatorii respectivelor clase;
elipsele sau cercurile - pentru atribute. In interior se specifica numele acestora;
romburile - pentru clasele de asociatii. Au inscrise in interior numele acestora;
liniile - pentru unirea simbolurilor precedente;
sagetile - pentru reprezentarea cardinalitatii.
O asociatie poate fi legata de mai multe entitati de acelasi tip, fiecare tip fiind identificabil. Cardinalitatea unei entitati dintr-o relatie este definita printr-o cifra plasata pe linia asociatiei. Ea poate fi 1:1, 1:N si M:N.
In figura nr. 4.13 este reprezentata grafic o diagrama Entitate-Asociatie dupa formalismul Chen.
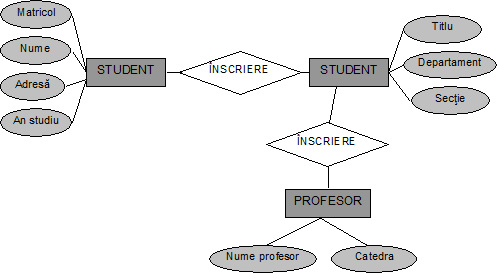
Fig. nr. 4.13 Diagrama Entitate-Asociatie in formalismul Chen
. Modelul obiectual
Aparitia acestui model este efectul orientarii spre multimedia si spre aplicatii de proiectare asistate de calculator care solicita prelucrarea tipurilor neconventionale de date.
La baza modelului orientat pe obiecte sta notiunea de entitate conceptuala definita ca un obiect descris printr-o colectie de proprietati. Principalele concepte care stau la baza unui model orientat pe obiecte sunt: obiectul, incapsularea, persistenta, clasa, tipul, mostenirea, polimorfismul, identitatea, domeniul.
Un obiect poate fi definit ca o abstractizare a unei entitati particulare sau ca un ansamblu de date, impreuna cu procedurile de prelucrare a acestora. Privite din acest punct de vedere procedurile poarta denumirea de metode, iar datele obiectului se numesc proprietati.
Un obiect este caracterizat prin atribute si comportament. Atributele reprezinta starea sa si legaturile care-l unesc cu alte obiecte, iar comportamentul se constituie din metodele si operatiile care pot fi aplicate atributelor.
Avand in vedere cele de mai sus, putem concluziona ca un obiect corespunde unei entitati care are un nume, stocheaza o stare (atribute) si raspunde unui ansamblu definit de mesaje.
Pot fi identificate trei tipuri de obiecte:
elementare: 20 (intreg), an I (sir de caractere), N (boolean);
compuse: nume, sectie, adresa;
complexe: student.
Un obiect este format din structura de date, specificarea operatiilor si implementarea operatiilor.
Interfata obiectului cu mediul o reprezinta mesajele care, de fapt sunt cereri adresate obiectului pentru a returna o valoare, sau pentru a-si schimba starea. Mesajele sunt implementate prin intermediul metodelor, care generic reprezinta programe de manipulare a obiectelor sau de indicare a starii acesteia.
Incapsularea reprezinta o caracteristica ce ofera utilizatorului o imagine functionala simplificata a obiectului, ascunzand complexitatea acestuia. Practic are loc divizarea obiectului in doua parti: interfata reprezentata de mesajele adresate obiectului si continutul obiectului reprezentat de starea interna si de metodele acestuia. Interfata permite unui utilizator din exterior sa solicite obiectului realizarea unei actiuni prin emiterea unui mesaj specific metodei asociate actiunii respective. Structura unei date obiect poate fi prezentata ca in fig. nr. 4.14.
Incapsularea urmareste ca datele unui obiect sa poata fi modificate doar prin intermediul metodelor proprii obiectului respectiv. In acest fel se realizeaza un control strict asupra obiectului, eliminandu-se eventualele surse de erori provenite din nefolosirea necorespunzatoare a proprietatilor[11]
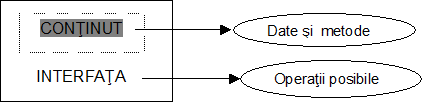
Fig. nr.4.14 Structura unei date obiect
Persistenta este proprietatea prin care datele si obiectele, ca existenta si stare, depasesc procesul care le-a creat, putand fi refolosite ulterior in alte procese.
Tipurile si clasele de obiecte sunt concepte care reunesc obiectele cu acelasi fel de atribute si comportament. Din aceasta perspectiva practica prezinta doua categorii de sisteme orientate pe obiecte:
sisteme bazate pe conceptul de tip (C++, Simula, vBase);
sisteme bazate pe conceptul de clasa (Smalltalk, Gemstone, Vision, Orion, G-Base).
Tipul sintetizeaza elementele comune ale obiectelor care au aceleasi caracteristici si dispune de doua componente: interfata si implementarea. Interfata se constituie dintr-o lista de operatii, iar implementarea asigura descrierea structurii interne a datelor, obiectului si realizarea procedurilor relative la operatiile interfetei.
Clasa are aceeasi semnificatie cu cea de tip, fiind asociata mai mult fazei de executie, presupunand generarea de obiecte si stocarea setului de obiecte. Rezulta ca o clasa descrie o colectie de obiecte ce au aceleasi atribute si acelasi comportament. Pentru a comunica intre ele si pentru a accede la informatiile unei alte entitati, obiectele isi trimit "mesaje". Acestea reprezinta numele metodelor si argumentele lor. Realizarea actiunii asociate unui mesaj depinde de obiectul receptor care isi administreaza propriile atribute folosind metode proprii[12]
Descrierea unei clase consta dintr-un set de structuri de date comune (variabile de instanta, care au propria identitate, identificatorii lor nefiind accesibili utilizatorilor), un protocol comun (set de mesaje la care vor raspunde instantele clasei) si un set de metode pentru implementarea operatiilor comune. In felul acesta descrierea clasei serveste ca sablon pentru crearea noilor obiecte. Ca urmare, obiectele din aceeasi clasa raspund la acelasi mesaj, au aceleasi atribute si folosesc aceleasi metode.
O problema aparte este legata de accesul utilizatorului la membrii unei clase printr-un mecanism de control care sa asigure protectia membrilor. Din acest punct de vedere membrii unei clase pot fi:
publici - accesibili atat din interiorul cat si din exteriorul clasei respective (dar din domeniul in care clasa a fost definita);
protejati - accesibili din interiorul clasei respective si a subclaselor construite pe baza acesteia (prin mostenire);
ascunsi - accesibili doar din interiorul clasei respective.
Clasele sunt organizate ierarhic, fiecare noua clasa fiind subordonata unei clase existente. Orice subclasa mosteneste structurile si metodele superclasei din care face parte.
Mostenirea reprezinta mecanismul de definire a unei clase prin preluarea variabilelor de instanta si a metodelor din una sau mai multe clase existente deja. In primul caz este vorba de o mostenire simpla, iar in cel de-al doilea de o mostenire multipla. Clasa de la care sunt mostenite (preluate) instantele (structurile de date) si metodele reprezinta o supraclasa. Clasa ce se creeaza mosteneste toate datele si metodele supraclasei, la care se vor adauga unele noi, definite pentru noua clasa. Astfel, pe baza principiului mostenirii pot fi create ierarhii de clase, incepand cu cele mai generale si ajungand la cele particulare, specializate in rezolvarea unei anumite sarcini de prelucrare.
Polimorfismul are in vedere comportamentul obiectelor care, la primirea unui mesaj, determina alegerea dinamica a metodei de aplicat, in functie de clasa corespunzatoare. Desi notiunea exista de mai mult timp (polimorfism ad-hoc, polimorfism parametric) ea a fost popularizata in special prin limbajele obiect. Polimorfismul asigura manipularea simpla si coerenta a seturilor eterogene de obiecte.
Utilizarea polimorfismului in cazul mostenirii multiple permite definirea unor forme complexe de comportament asigurand combinarea metodelor proprii mai multor clase de obiecte.
Identitatea reprezinta modalitatea de distingere a obiectelor intre ele, asigurand persistenta datelor. Prin identitate obiectele pot fi referite recursiv deoarece aceasta este independenta de valorile atributelor obiectelor. Identitatea unica a obiectelor se realizeaza prin intermediul unui identificator intern (numit ID Object sau Pointer), generat de sistem si inaccesibil utilizatorului.
La ora actuala nu exista un model propriu-zis pentru structurarea si functionarea unei baze de date orientate pe obiecte si aceasta in primul rand datorita naturaletei tehnologiei obiectuale[13]
[1] Saleh, I., Les bases de données relationnelles, Edition Hermes, Paris, 1995, p. 303
[2] Lungu, I. s.a., Baze de date - Organizare, proiectare si implementare, Editura All, Bucuresti, 1995, p.13
[3] Aceste elemente sunt numite diferit in literatura de specialitate - vezi Rosca, I., s.a., Baze de date si SGBD, Bucuresti, 1986; Lungu, I., s.a., Baze de date - Organizare, proiectare si implementare, Editura All, Bucuresti, 1995; Fotache, M., Baze de date relationale, Editura Junimea, Iasi, 1997
[4] Moréjon, J., Principes et conception d'un base de données relationnelle Les Editions d'organisation, Paris, 1992, p. 20
[5] Florescu, V. s.a. Baze de date, Editura Economica, Bucuresti, 1999, p. 32
[6] Moréjon, J., Op. cit., p. 26
[7] Moréjon, J., Op. cit., pp. 22-23
[8] Lungu, I. s.a., Op. cit., p. 96
[9] Fotache, M., Op. cit., p. 63
[10] Saleh, J., Les bases de donnees relationnelles, Edition Hermes, Paris, 1995, p. 22
[11] Dima, G., Dima, M., Bazele Visual FoxPro 5.0, Editura Teora, Bucuresti, 1999, p. 182
[12] Gaudel, M-C., s.a., Précis de génie logiciel, Edition Masson, Paris, Milan, Barcelon, 1996, p. 35
[13] Lungu, I. s.a., Op. cit., p. 220